오늘의 학습 내용
- 국내 제공 데이터셋 활용 연습
- 설문조사를 통한 데이터 수집
- Matplotlib에 의한 시각
- 외부 데이터셋 활용
오늘도 역시나 힘든 하루...!
어제 수업에 이어 pandas를 다루는 연습, 설문조사를 통해 데이터를 수집하는법, 응답 데이터를 통해 분석하기, 시각화 등 오늘은 정말 다양한 실습을 해서 시간이 정신없이 지나갔다
오늘 한 많은 실습과 내용중 어렵거나 중요하다고 생각한것만 간단히 뽑아 정리해보았다
데이터셋 활용
국내에서 제공하는 API, 데이터셋 중 오늘 실습에서는 서울 열린데이터 광장 (data.seoul.go.kr) 제공 데이터를 이용했다
두가지 데이터로 실습을 진행했는데 파일 용량 문제로 마지막에 진행한 실습만 정리!
mission
다음의 데이터셋을 pandas로 분석해서 서울시 용산구에서 광주광역시로 수송하는 것중 배송횟수가 가장 많은 날 찾기
import pandas as pd
df = pd.read_csv('서울 생활물류 (출발지) 서울 자치구 - (도착지) 전국시도.csv')
filtered_df = df[(df["송하인_구명"] == "용산구") & (df["수하인_시명"] == "광주광역시")]
grouped_df = filtered_df.groupby(["배송년월일", "송하인_구명", "수하인_시명"])[["대분류_착지물동량 가구/인테리어", "대분류_착지물동량 기타", "대분류_착지물동량 도서/음반", "대분류_착지물동량 디지털/가전", "대분류_착지물동량 생활/건강", "대분류_착지물동량 스포츠/레저", "대분류_착지물동량 식품", "대분류_착지물동량 출산/육아", "대분류_착지물동량 패션의류", "대분류_착지물동량 패션잡화", "대분류_착지물동량 화장품/미용"]].sum()
grouped_df["배송횟수"] = grouped_df.sum(axis=1)
grouped_df = grouped_df.rest_index()
grouped_df[["배송년월일", "송하인_구명", "수하인_시명", "배송횟수"]].sort_values(by="배송횟수", ascending=false).head(1)
설문조사를 통한 데이터 수집
1. 설문조사의 목적
1.1 고객 페르소나 구축 : 고객의 연령, 성별, 직업, 관심사 등 파악
1.2 제품/서비스 만족도 조사 : 고객이 제품을 어떻게 평가하는지 조사
1.3 광고/캠페인 효과 분석 : 특정 광고나 마케팅 캠페인이 효과가 있었는지 평가
1.4 구매 의사결정 과정 분석 : 고객이 제품을 구매하기까지 어떤 요인이 영향을 미쳤는지 확인
1.5 NPS(Net Promoter Score) 분석 : 고객의 브랜드 추천 의향 평가
2. 설문 설계와 분석
2.1 설문 설계
대상 : 최근 3개월 내 브랜드의 제품을 구매했거나, 마케팅 캠페인을 접한 고객
설문
[기본정보]
1. 연령대는 어떻게 되십니까? ① 10대 ② 20대 ③ 30대 ④ 40대 ⑤ 50대 이상
2. 성별을 선택해 주세요. ① 남성 ② 여성 ③ 기타
3. 현재 직업을 선택해 주세요. ① 학생 ② 직장인 ③ 자영업자 ④ 기타
[마케팅 캠페인 경험]
1. 최근 3개월 내 당사의 광고(유튜브, 인스타그램, 페이스북, 블로그 등)를 보신 적이 있습니까? ① 예 ② 아니오
2. 해당 광고를 접한 후 제품을 구매하셨습니까? ① 예 ② 아니오
3. 어떤 채널에서 광고를 접하셨습니까? (중복 선택 가능)
① 유튜브 ② 인스타그램 ③ 페이스북 ④ 네이버 블로그 ⑤ 기타
4. 해당 광고가 구매 결정에 얼마나 영향을 미쳤습니까? (1점: 전혀 영향 없음 ~ 5점: 매우 영향 큼)
① 1 ② 2 ③ 3 ④ 4 ⑤ 5
[브랜드 만족도 조사]
1. 제품 또는 서비스에 대한 전반적인 만족도를 평가해 주세요.
① 매우 불만족 ② 불만족 ③ 보통 ④ 만족 ⑤ 매우 만족
2. 제품을 다시 구매하거나 추천할 의향이 있습니까? ① 예 ② 아니오
3. 개선이 필요한 부분이 있다면 자유롭게 작성해 주세요. (주관식 응답)
2.2 설문 결과 분석
import pandas as pd
# 예제 설문 데이터 생성
data = {
"연령대": ["20대", "30대", "40대", "20대", "50대"],
"성별": ["남성", "여성", "여성", "남성", "남성"],
"광고_시청": ["예", "예", "아니오", "예", "예"],
"광고_채널": ["유튜브", "인스타그램", "없음", "페이스북", "네이버 블로그"],
"광고_영향": [5, 4, 0, 3, 2],
"제품_만족도": [4, 5, 3, 5, 2],
"재구매_의향": ["예", "예", "아니오", "예", "아니오"]
}
df = pd.DataFrame(data)
# 광고 시청 여부별 응답자 수 확인
ad_view_counts = df["광고_시청"].value_counts()
print("광고 시청 여부 분포:\n", ad_view_counts)
# 광고 채널별 응답자 수 확인
ad_channel_counts = df["광고_채널"].value_counts()
print("\n광고 채널별 분포:\n", ad_channel_counts)
# 제품 만족도 평균 값 계산
avg_satisfaction = df["제품_만족도"].mean()
print("\n제품 만족도 평균 값:", avg_satisfaction)
# 광고 영향도와 제품 만족도의 상관관계 확인
correlation = df[["광고_영향", "제품_만족도"]].corr()
print("\n광고 영향도와 제품 만족도의 상관관계:\n", correlation)
# 연령대별 광고 시청 여부 확인
age_ad_view = df.groupby("연령대")["광고_시청"].value_counts()
print("\n연령대별 광고 시청 여부:\n", age_ad_view)
# 재구매 의향 비율 계산
repurchase_rate = df["재구매_의향"].value_counts(normalize=True) * 100
print("\n재구매 의향 비율(%):\n", repurchase_rate)
# 광고 영향도 평균값
avg_ad_influence = df["광고_영향"].mean()
print("\n광고 영향도 평균 값:", avg_ad_influence)Matplotlib에 의한 시각화
Matplotlib : Python에서 데이터를 시각화할 때 사용하는 강력한 라이브러리
pip install matplotlib
1. 선 그래프 (Line Plot) : plt.plot()
# 예제
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [10, 20, 25, 30, 50]
plt.plot(x, y, marker='o', linestyle='-', color='b', label="Line Data")
plt.title("Line Graph Example")
plt.xlabel("X Axis")
plt.ylabel("Y Axis")
plt.legend() # 범례 추가
plt.grid(True) # 격자 추가
plt.show()
주요 매개변수
- x, y: X축, Y축 데이터
- marker: 점 모양 ('o', '*', 's', 'D', 'x' 등)
- linestyle: 선 스타일 ('-' 실선, '--' 점선, ':' 점선, '-.' 점-대시)
- color: 선 색상 ('r', 'g', 'b', '#FF5733' 등)
- label: 범례 추가
2. 바 그래프 (Bar Chart) : plt.bar ()
import matplotlib.pyplot as plt
categories = ["A", "B", "C", "D"]
values = [10, 25, 15, 30]
plt.bar(categories, values, color=['red', 'blue', 'green', 'purple'])
plt.title("Bar Chart Example")
plt.xlabel("Categories")
plt.ylabel("Values")
plt.show()
주요 매개변수
- categories: X축 레이
- values: Y축 값
- color: 각 막대의 색상 지정
- width: 막대의 너비 조정
3. 히스토그램 (Histogram) : plt.hist()
import matplotlib.pyplot as plt
import numpy as np
data = np.random.randn(1000) # 평균 0, 표준편차 1인 정규분포 데이터 생성
plt.hist(data, bins=30, color='skyblue', edgecolor='black')
plt.title("Histogram Example")
plt.xlabel("Value")
plt.ylabel("Frequency")
plt.show()
주요 매개변수
- data: 히스토그램을 만들 데이터
- bins: 막대의 개수 (구간 개수)
- color: 막대 색상
- edgecolor: 막대 테두리 색상
4. 산점도 (Scatter Plot) : plt.scatter()
import matplotlib.pyplot as plt
import numpy as np
x = np.random.rand(50)
y = np.random.rand(50)
plt.scatter(x, y, color='red', marker='o')
plt.title("Scatter Plot Example")
plt.xlabel("X Axis")
plt.ylabel("Y Axis")
plt.show()
주요 매개변수
- x, y: X축, Y축 데이터
- color: 점 색상
- marker: 점 모양 ('o', '*', 's', 'D', 'x' 등)
- s: 점 크기
5. 원형 그래프(Pie Chart) : plt.pie()
import matplotlib.pyplot as plt
sizes = [30, 20, 50]
labels = ["A", "B", "C"]
colors = ['red', 'blue', 'green']
plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors, startangle=90)
plt.title("Pie Chart Example")
plt.show()주요 매개변수
- sizes: 각 조각의 크기
- labels: 각 조각의 레이블
- autopct: 퍼센트 표시 형식
- color: 색상 지정
6. 서브플롯 (Subplot) : plt.subplot()
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1) # 1행 2열 중 첫 번째
plt.plot(x, y1, color='blue')
plt.title("Sine Wave")
plt.subplot(1, 2, 2) # 1행 2열 중 두 번째
plt.plot(x, y2, color='red')
plt.title("Cosine Wave")
plt.tight_layout() # 간격 자동 조정
plt.show()
주요 매개변수
- rows: 각 조각의 크기
- cols: 각 조각의 레이블
- index: 현재 그래프 위치
설문조사 데이터 분석 활용
1. 설문조사 예시 질문

2. 응답 데이터를 하드코딩하여 csv파일로 저장
import pandas as pd
# 설문조사 데이터 생성 (하드코딩된 응답 포함)
survey_data = pd.DataFrame({
"캠페인명": ["SNS 광고", "유튜브 광고", "이메일 마케팅", "인플루언서 협업", "검색 광고"],
"연령대": ["20대", "30대", "40대", "20대", "50대"],
"성별": ["남성", "여성", "여성", "남성", "남성"],
"광고_시청": ["예", "예", "아니오", "예", "예"],
"광고_채널": ["인스타그램", "유튜브", "없음", "페이스북", "구글 검색"],
"광고_영향": [5, 4, 0, 3, 2],
"제품_만족도": [4, 5, 3, 5, 2],
"재구매_의향": ["예", "예", "아니오", "예", "아니오"]
})
# CSV 파일로 저장
csv_filename = "growth_marketing_survey.csv"
survey_data.to_csv(csv_filename, index=False, encoding='utf-8-sig')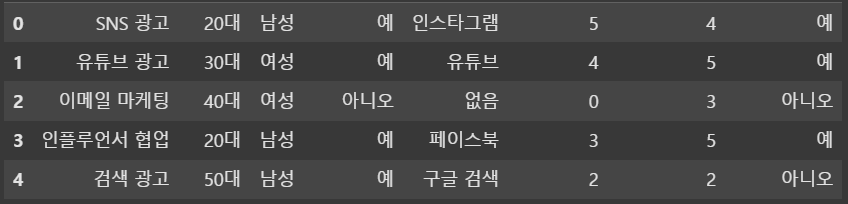
3.csv파일을 로드하여 데이터 분석
# 저장된 CSV 파일 불러오기
loaded_data = pd.read_csv(csv_filename)
# 데이터 개요 출력
print("데이터 개요:\n", loaded_data.info())
# 광고 시청 여부별 응답자 수 확인
ad_view_counts = loaded_data["광고_시청"].value_counts()
print("\n광고 시청 여부 분포:\n", ad_view_counts)
# 광고 채널별 응답자 수 확인
ad_channel_counts = loaded_data["광고_채널"].value_counts()
print("\n광고 채널별 분포:\n", ad_channel_counts)
# 제품 만족도 평균 값 계산
avg_satisfaction = loaded_data["제품_만족도"].mean()
print("\n제품 만족도 평균 값:", avg_satisfaction)
# 광고 영향도와 제품 만족도의 상관관계 확인
correlation = loaded_data[["광고_영향", "제품_만족도"]].corr()
print("\n광고 영향도와 제품 만족도의 상관관계:\n", correlation)
# 캠페인별 광고 영향도 평균 계산
campaign_impact = loaded_data.groupby("캠페인명")["광고_영향"].mean()
print("\n캠페인별 광고 영향도 평균:\n", campaign_impact)
# 캠페인별 제품 만족도 평균 계산
campaign_satisfaction = loaded_data.groupby("캠페인명")["제품_만족도"].mean()
print("\n캠페인별 제품 만족도 평균:\n", campaign_satisfaction)
# 재구매 의향 비율 계산
repurchase_rate = loaded_data["재구매_의향"].value_counts(normalize=True) * 100
print("\n재구매 의향 비율(%):\n", repurchase_rate)
# 광고 영향도 평균값
avg_ad_influence = loaded_data["광고_영향"].mean()
print("\n광고 영향도 평균 값:", avg_ad_influence)

4, 시각화를 통한 분석 결과








seaborn 에선 컬럼명이나 변수명에 한글이 들어가면 이처럼 오류가 나기 쉽다
예제 데이터라 한글이 섞여있지만 되도록 영어를 사용하는 것이 좋다!
"오늘의 회고"
뒤에 직접 설문을 설계하고 응답 데이터 생성하고 시각화 후 보고서까지 작성하는 과정이 있었는데
이에관한 내용만 뺴서 따로 포스팅하려고 한다.
어제,오늘 정말 힘들었다.. 뭔가 지치면서도 해내면 뿌듯하다가도 지치고.. 이 과정의 반복이다
그나마 블로그 챌린지를 함께하는 분들도 힘들다는 글을 보며 작은 위안이 된다,,

우리 서로 힘내면서 해봅시다..언젠가 강사님 말씀대로 편하게 보고서를 적는 날이 오겠죠..?
다들 오늘도 수고 많으셨어요....!!