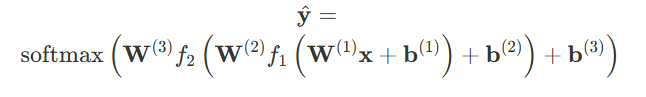오늘의 학습 내용 - ANN(Artificial Neural Network) - 다층신경망 - 결정 트리의 기본 개념과 구현 - 랜덤 포레스트 개념과 구현 - K-평균 군집화 개념과 구현
ANN(Artificial Neural Network)
인공신경망(Artificial Neural Network, ANN)은 인간의 뇌 구조를 모방한 기계 학습 모델로, 주로 패턴 인식, 분류, 예측 등의 문제 해결에 사용
1. Single layer & Multilayer Perceptron
1.1 Single Layer Perceptron (SLP):
입력 데이터 X = [1, 2, 3] 에 대해 하드코딩된 가중치 W = [0.2, 0.4, 0.6] 와 편향 b = 0.5을 적용하여 선형 변환을 수행
시그모이드 활성화 함수로 출력값을 계산
1.2 Multi-Layer Perceptron (MLP):
하드코딩된 가중치와 편향을 사용
첫 번째 은닉층 가중치 W1 는 4개의 뉴런이므로 4x3 크기, 편향 b1 는 4x1 크기
출력층 가중치 $W2$ 는 2개의 출력 뉴런이므로 2x4 크기, 편향 b2 는 2x1 크기
ReLU 활성화 함수를 은닉층에서 사용하고, 소프트맥스를 출력층에서 적용하여 각 클래스의 확률을 반환.
1.3 요약
SLP: 이진 분류 문제에서 단순한 예측 결과를 출력
MLP: 은닉층을 포함하여 더 복잡한 다중 클래스 분류 문제를 해결하는 구조
1.4 SLP와 MLP의 순전파만 보여주는 코드
Single Layer Perceptron (SLP)
import numpy as np
# 시그모이드 활성화 함수
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# SLP 구현 (하드 코딩된 가중치와 편향)
def forward_slp(X, W, b): # X: 입력값, w: 가중치, b: 절편값
Z = np.dot(W, X) + b # 선형 변환
A = sigmoid(Z) # 시그모이드 활성화 함수 적용
return A
# 입력 데이터 예시 (특징 3개)
X = np.array([[1], [2], [3]]) # 입력 데이터
# 하드코딩된 가중치와 편향
W = np.array([[0.2, 0.4, 0.6]]) # 1x3 크기 (하나의 노드)
b = np.array([[0.5]]) # 편향
# SLP 순전파
output_slp = forward_slp(X, W, b)
print("Single Layer Perceptron 출력:", output_slp)
각 뉴런은 활성화 함수(activation function)를 통해 입력 신호를 처리하며, 가중치(weight)와 편향(bias)을 포함하여 학습이 진행
2.1 주요 구성 요소
입력층(Input Layer): 데이터가 처음 들어오는 층
은닉층(Hidden Layer) :
입력층과 출력층 사시에 위치한 층
중요한 특징 추출이 이루어짐
hidden layer 1개는 회귀식 1개와 같다고 해석
hidden layer 0개: SLP / hidden layer 1개 이상: MLP/ hidden layer 3개 이상: 딥러닝(DNN)
출력층(Output Layer): 최종 예측 결과가 나오는 층(Soft Max사용:분류)
가중치(Weights): 각 연결에서 신호의 중요도를 나타냄
편향(Bias): 뉴런 활성화에 영향을 미치는 추가적인 요소
히든 레이어 1개 이상 : MLP/ 히든 레이어 3개 이상 : 딥러닝
다층신경망
1. 기본 구성
2. 수식 구성
▶ 최종 모델 수식 표현 :
이 식은 입력 \mathbf{x} 가 각 은닉층을 거쳐 활성화 함수를 통과하고,
최종적으로 소프트맥스 함수에 의해 확률로 변환되는 과정을 수식으로 나타낸 것
3. 신경망의 각 뉴런에서의 연산
1) 입력과 가중치의 곱을 계산한 뒤, 편향을 더함
2) 활성화 함수 적용. 활성화 함수는 뉴런의 출력이 어느 범위 내에 있도록 제한하며, 비선형성을 부여
시그모이드 함수와 ReLU
3) 오차 역전파(Backpropagation)
: 신경망을 학습시키는 과정에서, 출력과 실제 값 사이의 오차를 기반으로 가중치와 편향을 업데이트하는 과정
기울기 하강법(Gradient Descent)이 사용
sigmoid 함수: 은닉층과 출력층에서 사용하는 활성화 함수 순전파: 입력 데이터를 신경망을 통해 전달하여 예측값을 계산 역전파: 출력과 실제 값의 차이로부터 가중치에 대한 기울기를 계산하고, 이를 사용해 가중치를 업데이트 경사하강법: 학습률에 따라 가중치를 수정하여 손실을 줄여 나감
→ 오차 역전파 수행 코드 예제
import numpy as np
# 활성화 함수 (sigmoid) 및 그 도함수
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return sigmoid(x) * (1 - sigmoid(x))
# 손실 함수 (Mean Squared Error)
def loss(y_true, y_pred):
return 0.5 * np.mean((y_true - y_pred) ** 2)
# 데이터 (입력과 실제 출력)
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) # 입력 (XOR 문제)
y = np.array([[0], [1], [1], [0]]) # 실제 출력
# 가중치 및 편향 초기화 (무작위)
W1 = np.random.randn(2, 2) # 입력층 -> 은닉층 가중치
b1 = np.random.randn(1, 2) # 은닉층 편향
W2 = np.random.randn(2, 1) # 은닉층 -> 출력층 가중치
b2 = np.random.randn(1, 1) # 출력층 편향
# 학습률 설정
learning_rate = 0.1
# 순전파 및 역전파 실행
for epoch in range(10000): # 10,000번 반복 학습
# 순전파 (Forward Propagation)
z1 = np.dot(X, W1) + b1
a1 = sigmoid(z1)
z2 = np.dot(a1, W2) + b2
a2 = sigmoid(z2) # 예측 출력
# 손실 계산
loss_value = loss(y, a2)
# 역전파 (Backpropagation)
# 출력층 오차
dL_da2 = a2 - y # 손실의 출력층에 대한 기울기
dL_dz2 = dL_da2 * sigmoid_derivative(z2)
# 은닉층 -> 출력층 가중치 및 편향 업데이트
dL_dW2 = np.dot(a1.T, dL_dz2)
dL_db2 = np.sum(dL_dz2, axis=0, keepdims=True)
# 은닉층 오차
dL_da1 = np.dot(dL_dz2, W2.T)
dL_dz1 = dL_da1 * sigmoid_derivative(z1)
# 입력층 -> 은닉층 가중치 및 편향 업데이트
dL_dW1 = np.dot(X.T, dL_dz1)
dL_db1 = np.sum(dL_dz1, axis=0, keepdims=True)
# 가중치 및 편향 업데이트
W2 -= learning_rate * dL_dW2
b2 -= learning_rate * dL_db2
W1 -= learning_rate * dL_dW1
b1 -= learning_rate * dL_db1
if epoch % 1000 == 0:
print(f'Epoch {epoch}, Loss: {loss_value}')
# 최종 예측 값 출력
print("Final predictions:")
print(a2)
▷XOR 문제를 해결하기 위한 간단한 신경망이며, 각 에포크(epoch)마다 가중치가 업데이트되어 손실(loss)이 감소
4. 코드 표현
4.1 기본 코드 설명
# 1. 필요한 라이브러리 불러오기
import numpy as np
# 2. 활성화 함수 정의
## 은닉층에서 주로 사용되는 활성화 함수인 ReLU와 출력층에 적용되는 소프트맥스 함수를 정의
### ReLU 활성화 함수 정의
def relu(z):
return np.maximum(0, z)
### 소프트맥스 함수 정의
def softmax(z):
exp_z = np.exp(z - np.max(z)) # Overflow 방지를 위해 최대값을 뺌
return exp_z / np.sum(exp_z, axis=0)
# 3. 신경망 가중치 초기화
# 가중치 및 편향 초기화 함수 (랜덤)
def initialize_parameters(layer_dims):
np.random.seed(1)
parameters = {}
L = len(layer_dims) # 층의 개수
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l-1]) * 0.01
parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))
return parameters
#### layer_dims는 각 층의 뉴런 수를 정의한 리스트
#### 예를 들어, 입력층 3개 뉴런, 첫 번째 은닉층 4개 뉴런, 두 번째 은닉층 5개 뉴런, 출력층 3개 뉴런이라면 layer_dims = [3, 4, 5, 3]로 설정
# 4. 순전파 (Forward Propagation) 구현
def forward_propagation(X, parameters):
# 첫 번째 은닉층
W1 = parameters['W1']
b1 = parameters['b1']
Z1 = np.dot(W1, X) + b1
A1 = relu(Z1)
# 두 번째 은닉층
W2 = parameters['W2']
b2 = parameters['b2']
Z2 = np.dot(W2, A1) + b2
A2 = relu(Z2)
# 출력층
W3 = parameters['W3']
b3 = parameters['b3']
Z3 = np.dot(W3, A2) + b3
A3 = softmax(Z3) # 소프트맥스 적용
return A3
# 예시
# 입력 데이터 예시 (특징 수 3, 샘플 수 1)
X = np.array([[1], [2], [3]])
# 각 층의 뉴런 수를 정의 (입력층 3개, 은닉층 4개, 5개, 출력층 3개)
layer_dims = [3, 4, 5, 3]
# 가중치 및 편향 초기화
parameters = initialize_parameters(layer_dims)
# 순전파 실행
output = forward_propagation(X, parameters)
# 출력 결과
print("Softmax 확률 출력:", output)
4.2 다층신경망을 이용한 매출 예측
import numpy as np
# ReLU 활성화 함수 정의
def relu(z):
return np.maximum(0, z)
# ReLU 미분 함수 (Backpropagation에서 사용)
def relu_derivative(z):
return np.where(z > 0, 1, 0)
# 손실 함수 (Mean Squared Error)
def compute_loss(Y, A):
m = Y.shape[1] # 샘플 수
loss = np.mean((Y - A) ** 2) # MSE 계산
return loss
# 가중치 및 편향 초기화 함수
def initialize_parameters(layer_dims):
np.random.seed(1)
parameters = {}
for l in range(1, len(layer_dims)):
parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l-1]) * 0.01
parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))
return parameters
# 순전파 (Forward Propagation)
def forward_propagation(X, parameters):
cache = {}
# 첫 번째 은닉층
W1 = parameters['W1']
b1 = parameters['b1']
Z1 = np.dot(W1, X) + b1
A1 = relu(Z1)
# 두 번째 은닉층
W2 = parameters['W2']
b2 = parameters['b2']
Z2 = np.dot(W2, A1) + b2
A2 = relu(Z2)
# 출력층 (회귀 문제이므로 활성화 함수 없음)
W3 = parameters['W3']
b3 = parameters['b3']
Z3 = np.dot(W3, A2) + b3
A3 = Z3 # 출력층 활성화 함수는 사용하지 않음
# 캐시 저장 (역전파에서 사용)
cache['Z1'], cache['A1'] = Z1, A1
cache['Z2'], cache['A2'] = Z2, A2
cache['Z3'], cache['A3'] = Z3, A3
return A3, cache
# 역전파 (Backward Propagation)
def backward_propagation(X, Y, parameters, cache):
m = X.shape[1] # 샘플 수
grads = {}
# 출력층 오차
A3 = cache['A3']
dZ3 = A3 - Y
grads['dW3'] = np.dot(dZ3, cache['A2'].T) / m
grads['db3'] = np.sum(dZ3, axis=1, keepdims=True) / m
# 두 번째 은닉층 오차
dA2 = np.dot(parameters['W3'].T, dZ3)
dZ2 = dA2 * relu_derivative(cache['Z2'])
grads['dW2'] = np.dot(dZ2, cache['A1'].T) / m
grads['db2'] = np.sum(dZ2, axis=1, keepdims=True) / m
# 첫 번째 은닉층 오차
dA1 = np.dot(parameters['W2'].T, dZ2)
dZ1 = dA1 * relu_derivative(cache['Z1'])
grads['dW1'] = np.dot(dZ1, X.T) / m
grads['db1'] = np.sum(dZ1, axis=1, keepdims=True) / m
return grads
# 파라미터 업데이트 (경사 하강법)
def update_parameters(parameters, grads, learning_rate):
for l in range(1, len(parameters) // 2 + 1):
parameters['W' + str(l)] -= learning_rate * grads['dW' + str(l)]
parameters['b' + str(l)] -= learning_rate * grads['db' + str(l)]
return parameters
# 학습 데이터 생성 (하드코딩된 연도별 매출 데이터)
X_train = np.array([[2017, 2018, 2019, 2020, 2021]]) # 연도
Y_train = np.array([[100, 150, 200, 250, 300]]) # 해당 연도의 매출
# 데이터 정규화
X_train = X_train / 2021 # 연도를 최대값으로 나누어 정규화
Y_train = Y_train / 300 # 매출도 최대값으로 나누어 정규화
# 레이어 구성 (입력층 1, 은닉층 2개, 출력층 1개)
layer_dims = [1, 5, 3, 1]
# 파라미터 초기화
parameters = initialize_parameters(layer_dims)
# 학습 하이퍼파라미터
learning_rate = 0.01
num_iterations = 10000
# 학습 과정
for i in range(num_iterations):
# 순전파
A3, cache = forward_propagation(X_train, parameters)
# 손실 계산
loss = compute_loss(Y_train, A3)
# 역전파
grads = backward_propagation(X_train, Y_train, parameters, cache)
# 파라미터 업데이트
parameters = update_parameters(parameters, grads, learning_rate)
# 1000번마다 손실 출력
if i % 1000 == 0:
print(f"Iteration {i}, Loss: {loss:.4f}")
# 테스트 데이터 예측
X_test = np.array([[2022]]) # 테스트 데이터 (2022년)
X_test = X_test / 2021 # 정규화
# 순전파로 예측
A3_test, _ = forward_propagation(X_test, parameters)
# 예측 결과 출력 (2022년 매출 예측)
print("2022년 매출 예측 (원래 값):", A3_test * 300) # 원래 단위로 변환
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import os
# 경로 설정
base_dir = '/content/data' # 데이터 경로 설정
# 이미지 로드 및 전처리 (데이터 증강 없이)
train_datagen = ImageDataGenerator(
rescale=1./255, # 픽셀 값을 0-1 사이로 정규화
validation_split=0.2 # 데이터의 20%를 검증용으로 분리
)
# 학습 데이터 로드
train_generator = train_datagen.flow_from_directory(
base_dir, # 데이터가 저장된 디렉토리
target_size=(64, 64), # 이미지 크기 조정
batch_size=32, # 배치 크기
class_mode='binary', # 이진 분류
subset='training' # 학습 데이터
)
# 검증 데이터 로드
validation_generator = train_datagen.flow_from_directory(
base_dir, # 데이터가 저장된 디렉토리
target_size=(64, 64), # 이미지 크기 조정
batch_size=32, # 배치 크기
class_mode='binary', # 이진 분류
subset='validation' # 검증 데이터
)
# 다층 신경망 모델 구성
model = Sequential()
# 입력 데이터를 평탄화 (Flatten)하여 1차원으로 변환
model.add(Flatten(input_shape=(64, 64, 3))) # 이미지 크기가 64x64, RGB 채널 3개
# 은닉층 (뉴런 128개)
model.add(Dense(128, activation='relu'))
# 은닉층 (뉴런 64개)
model.add(Dense(64, activation='relu'))
# 출력층 (뉴런 1개, 시그모이드 활성화 함수 사용)
model.add(Dense(1, activation='sigmoid'))
# 모델 컴파일 (이진 분류, 손실 함수로 binary_crossentropy 사용)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 모델 학습
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // train_generator.batch_size,
epochs=10, # 에포크 수를 설정하여 학습 반복
validation_data=validation_generator,
validation_steps=validation_generator.samples // validation_generator.batch_size
)
# 모델 저장
model.save('dog_cat_classifier_mlp.h5')
# 테스트용 데이터로 예측
test_loss, test_acc = model.evaluate(validation_generator)
print(f"테스트 정확도: {test_acc}")
▷ 테스트 코드
import tensorflow as tf
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing import image
import numpy as np
# 모델 로드
model = load_model('dog_cat_classifier_mlp.h5')
# 테스트 이미지 경로
test_image_path = '/content/data/dog/dog (1).jpeg' # 테스트 이미지 경로를 지정
# 테스트 이미지 로드 및 전처리
def load_and_preprocess_image(img_path):
# 이미지를 64x64 크기로 로드하고 RGB로 변환
img = image.load_img(img_path, target_size=(64, 64))
# 이미지를 numpy 배열로 변환
img_array = image.img_to_array(img)
# 차원을 추가하여 (1, 64, 64, 3) 형태로 만듦 (모델 입력 차원과 맞춤)
img_array = np.expand_dims(img_array, axis=0)
# 이미지의 픽셀 값을 0-1 사이로 정규화
img_array /= 255.0
return img_array
# 이미지 로드 및 전처리
test_image = load_and_preprocess_image(test_image_path)
# 분류 예측
prediction = model.predict(test_image)
# 예측 결과 해석
if prediction[0] > 0.5:
print("이 이미지는 개일 가능성이 높습니다.")
else:
print("이 이미지는 고양이일 가능성이 높습니다.")
▷코드 결과
5.2 매출 예측 모델
▷ 예제 코드
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import r2_score
# 1. 하드코딩된 매출 데이터 생성 (30년간의 매출 데이터)
years = np.arange(1991, 2021) # 1991년부터 2020년까지의 30년간 데이터
sales = np.array([120, 135, 160, 180, 190, 220, 240, 260, 280, 300, 320, 350, 370, 390, 410,
430, 450, 470, 480, 500, 520, 530, 540, 560, 580, 600, 620, 640, 660, 680]) # 매출 데이터
# 2. 매출에 영향을 줄 수 있는 변수 생성
marketing_spend = np.array([80, 85, 90, 95, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200,
210, 220, 230, 240, 250, 260, 270, 280, 290, 300, 310, 320, 330, 340, 350]) # 마케팅 비용
economy_index = np.array([1.0, 1.1, 0.9, 1.2, 1.0, 0.8, 1.1, 1.0, 0.9, 1.2, 1.0, 1.1, 1.0, 0.9, 1.2,
1.0, 0.8, 1.1, 1.0, 0.9, 1.2, 1.0, 1.1, 1.0, 0.9, 1.2, 1.0, 0.9, 1.2, 1.0]) # 경제 지수
# 3. 데이터를 Pandas DataFrame으로 처리
data = pd.DataFrame({
'Year': years,
'Sales': sales,
'Marketing_Spend': marketing_spend,
'Economy_Index': economy_index
})
print(data.head()) # 데이터 미리보기
# 4. 입력 변수(X)와 출력 변수(y)를 정의
X = data[['Year', 'Marketing_Spend', 'Economy_Index']].values # 연도, 마케팅 비용, 경제 지수
y = data['Sales'].values # 매출
# 5. 데이터 정규화 (입력 데이터 스케일 조정)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # X 데이터를 정규화
# 6. 다층 신경망 모델 정의
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=(X_scaled.shape[1],))) # 은닉층 1 (뉴런 128개로 증가)
model.add(Dense(64, activation='relu')) # 은닉층 2 (뉴런 64개로 증가)
model.add(Dense(32, activation='relu')) # 은닉층 3 추가 (뉴런 32개)
model.add(Dense(1)) # 출력층 (매출 예측)
# 7. 모델 컴파일 (learning_rate를 조정)
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001) # 학습률 0.001로 설정
model.compile(optimizer=optimizer, loss='mean_squared_error')
# 8. 모델 학습 (Epochs와 Batch Size를 조정)
model.fit(X_scaled, y, epochs=500, batch_size=10, verbose=1) # 에포크 수 증가, 배치 크기 감소
# 9. 모델 성능 측정 (R² 값 계산)
y_pred = model.predict(X_scaled)
# R² 계산
r2 = r2_score(y, y_pred)
print(f"R² 값: {r2:.4f}")
# 10. 특정 연도의 매출 예측
def predict_sales(year, marketing_spend, economy_index):
# 예측할 데이터를 정규화
input_data = np.array([[year, marketing_spend, economy_index]])
input_data_scaled = scaler.transform(input_data)
# 예측 수행
predicted_sales = model.predict(input_data_scaled)
return predicted_sales[0][0]
# 예시: 2025년의 매출 예측
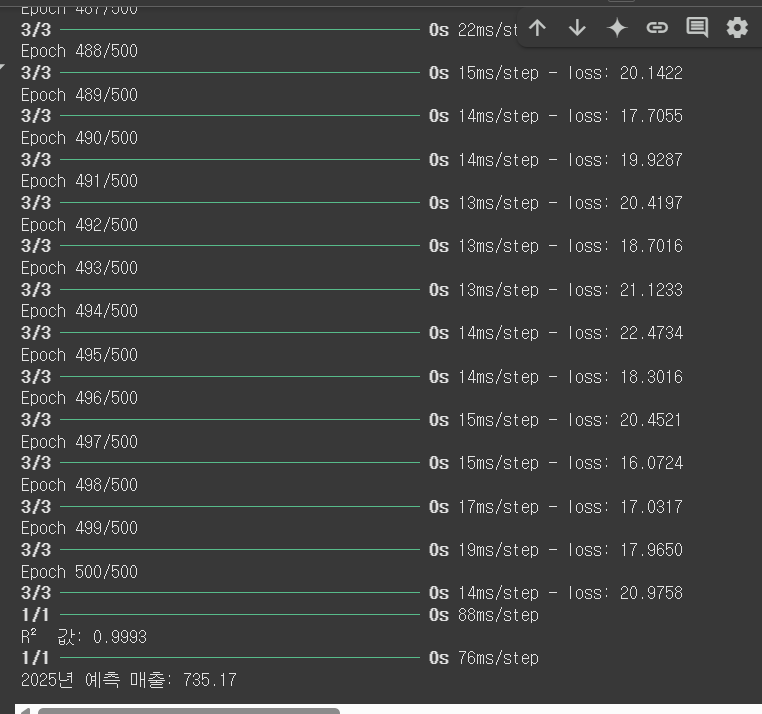
predicted_sales_2025 = predict_sales(2025, 360, 1.05)
print(f"2025년 예측 매출: {predicted_sales_2025:.2f}")
▷ 코드 결과
6. teachable machine 이용 실습(web서버 연동)
teachable machine 이용 하여 이미지 분류 모델 웹서버 연동 기본 준비 1. 분류하고자 하는 이미지 수집 2. teachable machine을 이용해 이미지 분류 모델 생성 3. 모델 내보내기 클릭후 tensorflow 클릭하여 모델 다운
4. 코드 작성하여 app.py, index.html, result.html 파일 생성 5. 다음과 같은 디렉토리 설정
/프로젝트_폴더
│── app.py # Flask 실행 파일
│── keras_model.h5 # Teachable Machine에서 내보낸 모델 파일
│── labels.txt # Teachable Machine에서 내보낸 클래스 레이블 파일
│── templates/
│ ├── index.html # 업로드 페이지
│ ├── result.html # 결과 페이지
│── uploads/ # 업로드된 이미지가 저장되는 폴더
결정 트리(Decision Tree)는 데이터를 기반으로 의사 결정을 내리는 트리 형태의 모델
트리는 노드(Node)와 가지(Branch)로 이루어져 있으며, 각 노드는 특정 속성(Feature)에 대한 조건을 기반으로 데이터를 분류하거나 회귀 분석을 수행
(기본 이론은 어제 했던 수업과 겹쳐 생략하고 실습 위주로 정리)
1. 결정 트리 구현
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 데이터 로드
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
# 결정 트리 모델 학습
clf = DecisionTreeClassifier(max_depth=3, random_state=42)
clf.fit(X_train, y_train)
# 예측 및 정확도 평가
y_pred = clf.predict(X_test)
print("정확도:", accuracy_score(y_test, y_pred))
랜덤 포레스트(Random Forest) 개념과 구현
랜덤 포레스트(Random Forest)는 여러 개의 결정 트리를 결합하여 예측 성능을 향상시키는 앙상블 학습 방법
분류와 회귀 문제 모두에 사용할 수 있으며, 노이즈에 강하고 안정적인 예측을 제공
1. 랜덤 포레스트의 기본 개념
랜덤 포레스트는 배깅(Bagging)과 특징 샘플링을 이용하여 다수의 결정 트리를 학습하고 이를 종합하여 최종 예측을 수행
배깅(Bootstrap Aggregating): 주어진 데이터에서 여러 개의 샘플을 랜덤하게 뽑아 각 결정 트리를 학습시키는 방법
특징 샘플링(Feature Sampling): 각 트리가 학습할 때 전체 특성 중 일부만 선택하여 학습하는 방식
예측 방식:
분류 문제에서는 다수결 투표(Majority Voting) 방식을 사용하여 가장 많이 예측된 클래스를 최종 결과로 선택
회귀 문제에서는 개별 트리의 평균값을 최종 예측값으로 사용
2. 랜덤 포레스트의 작동 원리
원본 데이터에서 여러 개의 랜덤 샘플을 생성하여 각각 독립적인 결정 트리를 학습시킨다.
각 결정 트리는 일부 특성만을 사용하여 최적의 분할을 찾는다.
새로운 입력 데이터가 주어지면 학습된 여러 개의 결정 트리가 각각 예측을 수행한다.
분류 문제에서는 다수결 투표 방식으로 최종 클래스를 결정하고, 회귀 문제에서는 평균을 계산하여 최종 예측값을 구한다.
3. 랜덤 포레스트의 장점과 단점
3.1 장점
여러 개의 트리를 결합하므로 단일 결정 트리보다 일반화 성능이 우수
과적합 가능성이 낮음
변수 중요도를 제공하여 데이터 분석에도 유용
이상치와 결측치에 강함
3.2 단점
다수의 트리를 생성해야 하므로 학습 및 예측 속도가 상대적으로 느릴 수 있음
해석이 어려움. 랜덤 포레스트는 여러 트리가 결합된 모델이므로 해석이 복잡할 수 있음
4. 랜덤 포레스트 구현 : 그로스마케팅 예측
4.1 전자상거래 고객 지출 금액 예측
어떤 전자상거래 기업이 고객의 과거 구매 데이터와 행동 패턴을 분석하여 향후 한 달 동안 각 고객이 지출할 금액을 예측하려 한다. 이를 위해 고객의 구매 이력, 웹사이트 방문 빈도, 이전 구매 금액 등의 데이터를 사용하여 랜덤 포레스트 회귀(Random Forest Regression)를 적용한다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# 1. 샘플 데이터 생성 (고객 행동 데이터)
np.random.seed(42)
num_customers = 200
data = pd.DataFrame({
'Customer_ID': range(1, num_customers + 1),
'Previous_Spending': np.random.randint(50, 500, size=num_customers), # 이전 총 구매 금액 ($)
'Visit_Frequency': np.random.randint(1, 20, size=num_customers), # 웹사이트 방문 빈도 (월 단위)
'Average_Order_Value': np.random.randint(10, 200, size=num_customers), # 평균 주문 금액 ($)
'Discount_Used': np.random.choice([0, 1], size=num_customers), # 할인 사용 여부 (0: 사용 안 함, 1: 사용)
'Future_Spending': np.random.randint(50, 600, size=num_customers) # 향후 한 달 동안의 예상 지출 ($)
})
# 2. 독립 변수(X)와 종속 변수(y) 설정
X = data[['Previous_Spending', 'Visit_Frequency', 'Average_Order_Value', 'Discount_Used']]
y = data['Future_Spending']
# 3. 훈련 데이터와 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 4. 랜덤 포레스트 회귀 모델 학습
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 5. 예측 수행
y_pred = model.predict(X_test)
# 6. 모델 성능 평가
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Absolute Error (MAE): {mae:.2f}")
print(f"Mean Squared Error (MSE): {mse:.2f}")
print(f"R² Score: {r2:.2f}")
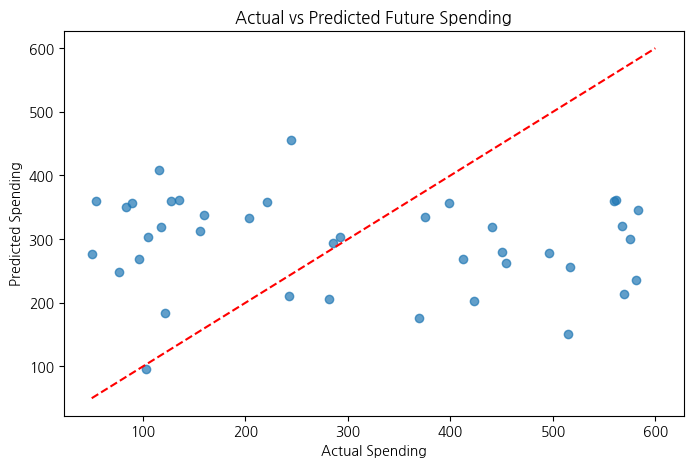
# 7. 예측 결과 시각화
plt.figure(figsize=(8, 5))
plt.scatter(y_test, y_pred, alpha=0.7)
plt.xlabel("Actual Spending")
plt.ylabel("Predicted Spending")
plt.title("Actual vs Predicted Future Spending")
plt.plot([50, 600], [50, 600], color="red", linestyle="dashed") # y=x 선
plt.show()
4.2 결혼 예측 모델 개발
한국에서 결혼 성공에 영향을 미치는 요소를 검토해 독립변수로 만들고 예측 모델을 개발한다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import seaborn as sns
# 1. 한국 상황에 맞춘 연애 데이터 생성 (학력, 직장 추가)
data = pd.DataFrame({
'연애기간(년)': [1, 2, 3, 5, 6, 1, 4, 2, 7, 3, 8, 6, 9, 10, 3, 5, 2, 7, 4, 6],
'경제력(연봉:백만원)': [3000, 2500, 4000, 5000, 5500, 2000, 4200, 2800, 6000, 2300, 7000, 5000, 1800, 1500, 3200, 4800, 2700, 5800, 3500, 4600],
'경제권(남자:0, 여자:1, 각자:2)': [0, 2, 1, 0, 0, 1, 2, 2, 0, 1, 2, 0, 1, 0, 2, 2, 0, 1, 0, 1],
'상대 가족 행사 참석율(%)': [100, 80, 60, 90, 70, 50, 30, 40, 100, 80, 60, 50, 20, 10, 40, 70, 80, 60, 90, 30],
'종교차이여부(0:없음,1:있음)': [0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0],
'외모 중요도(1: 낮음, 2: 보통, 3: 높음)': [3, 2, 1, 3, 2, 1, 2, 2, 3, 1, 3, 2, 1, 1, 2, 3, 2, 3, 3, 2],
'결혼 후 자녀 계획(명)': [2, 1, 2, 3, 3, 1, 2, 1, 3, 1, 3, 2, 1, 1, 2, 3, 1, 3, 2, 3],
'직장안정성(1:불안정,2:보통,3:안정적)': [2, 1, 3, 3, 3, 1, 2, 1, 3, 1, 3, 3, 1, 1, 2, 3, 1, 3, 2, 3],
'결혼성공(1:성공, 0:실패)': [1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0]
})
# 2. 독립 변수(X)와 종속 변수(y) 설정
X = data[['연애기간(년)', '경제력(연봉:백만원)', '경제권(남자:0, 여자:1, 각자:2)', '상대 가족 행사 참석율(%)',
'종교차이여부(0:없음,1:있음)', '외모 중요도(1: 낮음, 2: 보통, 3: 높음)', '결혼 후 자녀 계획(명)', '직장안정성(1:불안정,2:보통,3:안정적)']]
y = data['결혼성공(1:성공, 0:실패)']
# 3. 훈련 데이터와 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 4. 랜덤 포레스트 분류 모델 학습
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 5. 테스트 데이터 예측 수행
y_pred = model.predict(X_test)
# 6. 모델 평가
accuracy = accuracy_score(y_test, y_pred)
print(f"정확도: {accuracy:.2f}")
print("\n분류 보고서:\n", classification_report(y_test, y_pred))
# 7. 새로운 데이터 입력 (연애 기간, 경제력, 성격 차이 등으로 결혼 성공 여부 예측)
new_data = pd.DataFrame({
'연애기간(년)': [4],
'경제력(연봉:백만원)': [4500],
'경제권(남자:0, 여자:1, 각자:2)': [1],
'상대 가족 행사 참석율(%)': [70],
'종교차이여부(0:없음,1:있음)': [1],
'외모 중요도(1: 낮음, 2: 보통, 3: 높음)': [2],
'결혼 후 자녀 계획(명)': [1],
'직장안정성(1:불안정,2:보통,3:안정적)': [3]
})
predicted_success = model.predict(new_data)
print(f"새로운 연애 데이터에 대한 결혼 성공 예측 결과: {'성공' if predicted_success[0] == 1 else '실패'}")
# 8. 혼동 행렬 시각화
plt.figure(figsize=(5, 4))
sns.heatmap(confusion_matrix(y_test, y_pred), annot=True, fmt="d", cmap="Blues", xticklabels=["실패", "성공"], yticklabels=["실패", "성공"])
plt.xlabel("예측값")
plt.ylabel("실제값")
plt.title("결혼 성공 예측 - 혼동 행렬")
plt.show()
K-평균 군집화(K-Means Clustering)는 데이터를 K개의 그룹으로 나누는 군집화(Clustering) 알고리즘
주어진 데이터에서 각 데이터 포인트를 가장 가까운 중심(centroid)으로 할당하고, 중심을 반복적으로 업데이트하여 최적의 군집을 찾는 것으로 이는 비지도 학습에 해당
1. K-평균 군집화의 기본 개념
K-평균 군집화는 다음과 같은 단계를 반복하여 최적의 군집을 형성함
데이터에서 K개의 중심(centroid)을 무작위로 초기화한다.
각 데이터 포인트를 가장 가까운 중심에 할당하여 군집을 형성한다.
각 군집의 중심을 다시 계산하여 새로운 중심을 찾는다.
새로운 중심을 기준으로 다시 군집을 할당하고, 중심이 더 이상 변화하지 않을 때까지 이 과정을 반복한다.
K-평균 알고리즘은 사용자가 미리 K값을 정해야 한다는 단점이 있음
최적의 K값을 찾기 위해 엘보우(Elbow) 기법과 실루엣(Silhouette) 점수와 같은 방법을 사용할 수 있음
최적의 K값을 찾는 방법 : 엘보우 기법과 실루엣 점수
엘보우 기법(Elbow Method): K값에 따른 군집 내 변동 값(Inertia)을 계산하여, 그래프의 기울기가 급격히 완만해지는 지점(엘보우 포인트)을 최적의 K값으로 선택 실루엣 점수(Silhouette Score): 각 데이터 포인트가 자신의 군집과 얼마나 밀접하게 묶여 있으며, 다른 군집과는 얼마나 분리되어 있는지를 평가하는 지표. 실루엣 점수가 높을수록 군집화가 잘 되어 있음을 의미
→ 엘보우 기법 & 실루엣 점수 이용 코드 예제
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.datasets import make_blobs
# 샘플 데이터 생성
np.random.seed(42)
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=1.0, random_state=42)
# 엘보우 기법 이용
# K 값별 관성(Inertia) 저장
inertia = []
k_range = range(1, 11)
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(X)
inertia.append(kmeans.inertia_)
# 엘보우 차트 그리기
plt.figure(figsize=(8, 5))
plt.plot(k_range, inertia, marker='o')
plt.xlabel("Number of Clusters (K)")
plt.ylabel("Inertia")
plt.title("Elbow Method for Optimal K")
plt.xticks(k_range)
plt.show()
# 실루엣 점수를 이용
# K 값별 실루엣 점수 저장
silhouette_scores = []
for k in range(2, 11): # 실루엣 점수는 최소 2개 이상의 클러스터가 필요
kmeans = KMeans(n_clusters=k, random_state=42)
labels = kmeans.fit_predict(X)
silhouette_scores.append(silhouette_score(X, labels))
# 실루엣 점수 그래프 그리기
plt.figure(figsize=(8, 5))
plt.plot(range(2, 11), silhouette_scores, marker='o', color='red')
plt.xlabel("Number of Clusters (K)")
plt.ylabel("Silhouette Score")
plt.title("Silhouette Score for Optimal K")
plt.xticks(range(2, 11))
plt.show()
2. K-평균 군집화의 장점과 단점
2.1 장점
계산 속도가 빠르고 대규모 데이터에서도 비교적 효율적.
해석이 용이하며 직관적인 알고리즘
특정 분야(이미지 분할, 고객 세분화 등)에서 널리 사용
2.2 단점
K값을 미리 설정해야 하며, 잘못된 K값 선택은 성능 저하를 초래
원형 군집이 아닌 경우(예: 타원형 또는 비선형 구조) 성능이 낮을 수 있음
이상치(Outlier)에 민감하여 중심값이 왜곡될 가능성이 있음
3. K-평균 군집화 구현
3.1 고객 세분화
시나리오 온라인 쇼핑몰에서 고객 데이터를 분석하여 비슷한 소비 패턴을 가진 고객들을 그룹화할 수 있다. 고객의 연간 구매 금액, 구매 빈도, 방문 횟수 등의 데이터를 기반으로 K-평균 군집화를 수행하면, VIP 고객, 일반 고객, 신규 고객 등의 그룹을 나눌 수 있다. 이를 통해 맞춤형 마케팅 전략을 수립할 수 있다.
▶ 예제 코드
from sklearn.preprocessing import StandardScaler
import pandas as pd
# 샘플 고객 데이터 생성
data = {
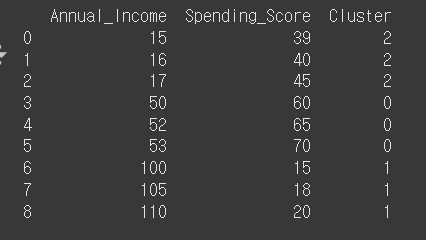
"Annual_Income": [15, 16, 17, 50, 52, 53, 100, 105, 110],
"Spending_Score": [39, 40, 45, 60, 65, 70, 15, 18, 20]
}
df = pd.DataFrame(data)
# 데이터 정규화
scaler = StandardScaler()
scaled_data = scaler.fit_transform(df)
# K-평균 군집화 수행
kmeans = KMeans(n_clusters=3, random_state=42)
df["Cluster"] = kmeans.fit_predict(scaled_data)
print(df)
▶ 결과
3.2 이미지 색상 압축
시나리오 이미지의 색상을 줄이는 데 K-평균 군집화를 사용할 수 있다. 예를 들어, 고해상도 이미지에서 1,000만 개의 색상을 단 16개의 색상으로 줄이면, 압축된 이미지를 생성할 수 있다.
▶ 예제 코드
from sklearn.cluster import KMeans
from skimage import io
import numpy as np
# 이미지 로드
image = io.imread("sample.jpg")
pixels = image.reshape(-1, 3)
# K-평균 군집화 적용
kmeans = KMeans(n_clusters=16, random_state=42)
kmeans.fit(pixels)
compressed_pixels = kmeans.cluster_centers_[kmeans.labels_]
compressed_image = compressed_pixels.reshape(image.shape)
# 압축된 이미지 시각화
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title("Original Image")
plt.axis("off")
plt.subplot(1, 2, 2)
plt.imshow(compressed_image.astype(np.uint8))
plt.title("Compressed Image (16 Colors)")
plt.axis("off")
plt.show()
▶ 결과
3.3 이상치 탐지
시나리오 K-평균 군집화를 사용하여 정상적인 데이터 포인트와 이상치를 구별할 수 있다. 예를 들어, 은행 거래 데이터를 분석하여 비정상적인 거래(사기)를 탐지하는 데 활용할 수 있다.