오늘의 학습 내용
- 데이터 전처리와 특징 엔지니어링
- 선형 회귀 개념과 원리
- 다중 선형 회귀와 모델 평가
- 로지스틱 회귀 개념과 활용
- 모델 성능 평가와 다중 분류
데이터 전처리와 특징 엔지니어링
머신러닝 모델의 성능은 데이터의 품질에 크게 의존
데이터를 제대로 정리하고, 적절한 특징(Feature)을 만들어내는 과정이 매우 중요
이를 위해 데이터 전처리(Data Preprocessing)와 특징 엔지니어링(Feature Engineering)을 수행해야 함
1. 데이터 전처리(Data Preprocessing)
1.1 데이터 정리 및 탐색
데이터를 정리하고 구조를 이해하는 단계
- 데이터 로드: pandas, NumPy 등을 활용하여 데이터를 불러옴
- 기초 통계 확인: df.describe(), df.info() 등을 이용하여 데이터 타입과 분포 확인
- 데이터 시각화: matplotlib, seaborn을 사용해 변수 간 관계 파악
1.2 결측값(Missing Values) 처리
결측값은 데이터셋에 값이 없는 부분을 의미
적절히 처리하지 않으면 모델의 성능이 저하될 수 있음
결측값 확인
import pandas as pd
df.isnull().sum() # 결측값 개수 확인
결측값 처리 방법
# 1. 삭제
df.dropna(inplace=True)
# 2. 대체
df.fillna(df.mean(), inplace=True) # 평균값으로 대체
df.fillna(df.median(), inplace=True) # 중앙값으로 대체
df.fillna(df.mode().iloc[0], inplace=True) # 최빈값으로 대체
# 3. 예측 모델 활용: 머신러닝 모델을 이용해 결측값을 예측하고 보완1.3 이상치(Outliers) 처리
이상치는 데이터 분포에서 벗어난 극단적인 값으로, 모델 성능을 저하 시킬 수 있음
이상치 탐색
# 1. 박스플롯(Box Plot) 활용
import seaborn as sns
sns.boxplot(x=df['feature_column'])
# 2. Z-Score 활용
from scipy import stats
z_scores = stats.zscore(df['feature_column'])
df = df[(z_scores < 3)] # Z-score가 3 이상이면 이상치로 간주하여 제거
# 3. IQR(Interquartile Range, 사분위 범위) 활용
Q1 = df['feature_column'].quantile(0.25)
Q3 = df['feature_column'].quantile(0.75)
IQR = Q3 - Q1
df = df[(df['feature_column'] >= Q1 - 1.5 * IQR) & (df['feature_column'] <= Q3 + 1.5 * IQR)]
이상치 처리 방법
- 제거(Removal): 이상치를 제거하는 방식
- 대체(Replacement): 중앙값 또는 평균값으로 변경
- 변환(Transformation): 로그 변환, 제곱근 변환 등 사용
1.4 데이터 정규화 및 스케일링
특징 값(Feature Value)의 크기가 다를 경우 모델 성능에 영향을 미칠 수 있으므로 스케일링을 수행
정규화(Normalization)
표준화(Standardization)
2. 특징 엔지니어링 (Feature Engineering)
특징 엔지니어링은 모델이 학습할 수 있도록 적절한 특징을 생성하거나 변환하는 과정
2.1 새로운 특징 생성
새로운 변수(Feature)를 추가하여 모델의 성능을 향상
# 기존 변수 조합
df['BMI'] = df['Weight'] / (df['Height']**2)
# 날짜 정보 변환
df['date'] = pd.to_datetime(df['date'])
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df['weekday'] = df['date'].dt.weekday # 0: 월요일, 6: 일요일
# 텍스트 데이터 변환
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(df['text_column'])
2.2 특징 선택
모든 변수를 사용하는 것이 아니라, 모델 성능을 높이는 중요한 변수만 선택하는 과정
# 높은 상관관계를 가진 변수만 선택
import seaborn as sns
import matplotlib.pyplot as plt
corr_matrix = df.corr()
sns.heatmap(corr_matrix, annot=True, cmap="coolwarm")
# 중요도 기반 선택 : 포레스트 모델을 사용해 변수 중요도를 확인
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
feature_importances = pd.Series(model.feature_importances_, index=X_train.columns)
feature_importances.sort_values(ascending=False).plot(kind='bar')
2.3 특징 변환
특징을 변환하여 데이터의 분포를 변경하거나 차원을 축소하는 기법
# 로그 변환(Log Transformation) : 분포가 오른쪽으로 치우쳐 있는 경우 로그 변환을 통해 정규 분포에 가깝게 만듦
df['feature'] = np.log1p(df['feature'])
# 차원 축소(Dimensionality Reduction) : PCA(주성분 분석)을 이용해 특징 차원을 줄임
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
선형회귀분석의 개념
회귀분석은 통계학에서 두 개 이상의 변수 사이의 관계를 분석하고 예측 모델을 구축하는 기법
주요 구성요소
1. 주요 구성요소
- 종속 변수 (Dependent Variable, Y):
분석의 목표가 되는 변수
- 독립 변수 (Independent Variable, X):
종속 변수에 영향을 주는 변수
- 오차항 (Error Term, ε):
모델이 설명하지 못하는 부분, 즉 관측된 값과 예측된 값 사이의 차이
측정오차나 누락된 변수 등 여러 요인에 의해 발생
2. 회귀모델의 형태
선형(linear) 또는 비선형(nonlinear) 형태를 가질 수 있음
대표적인 방법으로 최소제곱법(OLS, Ordinary Least Squares)을 사용하여 모델의 파라미터를 추정
3. 단순 회귀 분석
하나의 독립 변수와 하나의 종속 변수 사이의 선형 관계를 모델링하는 가장 기본적인 형태의 회귀분석
3.1 모델 수식

- beta_0 (절편, Intercept): 독립 변수 X의 값이 0일 때 예상되는 종속 변수 Y의 값
- beta_1 (기울기, Slope): X가 한 단위 증가할 때 Y가 평균적으로 얼마나 증가(또는 감소)하는지를 나타냄
- varepsilon (오차항): 모델이 설명하지 못한 변동성
3.2 최소제곱법 (OLS)
단순 회귀 분석에서는 최소제곱법을 통해 B0(베타)와 B1를 추정
이 방법은 각 관측치에서 예측값과 실제값 사이의 잔차(residual)의 제곱합을 최소화하는 파라미터를 찾는 방법
잔차 분석
: 잔차를 분석하면 모델이 데이터의 변동성을 얼마나 잘 설명하는지, 이상치나 패턴이 존재하는지 확인 가능
4. 회귀분석의 기본 가정
4.1 선형성 (Linearity)
독립 변수와 종속 변수 간의 관계가 선형이라는 가정
데이터가 선형적이지 않을 경우 비선형 변환이나 다른 모델링 기법이 필요할 수 있음
4.2 독립성 (Independence)
각 관측치가 서로 독립적이어야 함
시계열 데이터의 경우 자기상관 문제가 발생할 수 있으며, 이를 확인하고 보정할 필요가 있음
4.3 등분산성 (Homoscedasticity)
모든 수준의 독립 변수에서 오차의 분산이 동일하다는 가정
만약 오차의 분산이 일정하지 않다면(이분산성), 모델의 추정치가 왜곡될 수 있음
4.4 정규성 (Normality)
오차항이 정규분포를 따른다는 가정
이는 주로 추정치의 신뢰구간 및 가설 검정에서 중요한 역할을 하며, 정규성 검정을 통해 확인할 수 있음
5. 모델 적합도 평가 및 검정
5.1 결정계수 (R²)
종속 변수의 변동 중에서 모델이 설명하는 비율
0과 1 사이의 값을 가지며, 1에 가까울수록 모델의 설명력이 좋음을 의미
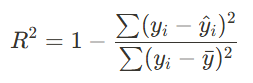
의미 :
- R² 값이 1에 가까울수록 모델이 데이터를 잘 설명함을 의미
- R² = 0이면 모델이 평균값만큼도 설명하지 못한다는 뜻
- R² 가 음수일 수도 있으며, 이는 모델이 데이터 설명에 실패하고 있음(즉, 평균값을 그대로 예측하는 것보다 성능이 나쁨)을 의미합니다.
5.2 t-검정 및 p-값
- t-검정: 각 회귀계수가 통계적으로 유의한지를 검정
- p-값: 기울기나 절편이 0이라는 귀무가설을 기각할 수 있는지 판단 (대체로 p-값이 0.05 미만일때 유의하다고 봄)
5.3 F-검정
전체 모델의 유의성을 검정하는 방법으로, 독립 변수가 종속 변수의 변동을 설명하는 데 유의한지를 평가
6. 회귀분석에 대한 그로스 마케팅 보고서
▶ 예제 데이터

▶ 코드 예제
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
# 1. 가상의 데이터 준비
data = {
'ad_spend': [1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10000],
'conversions': [120, 150, 180, 210, 240, 265, 290, 320, 345, 370]
}
df = pd.DataFrame(data)
# 2. 독립 변수(X)와 종속 변수(y) 설정
X = df[['ad_spend']]
y = df['conversions']
# 3. 단순 회귀 모델 생성 및 학습
model = LinearRegression()
model.fit(X, y)
# 4. 모델 파라미터 및 결정계수(R²) 출력
intercept = model.intercept_
slope = model.coef_[0]
r2 = r2_score(y, model.predict(X))
print("회귀식: 전환수 = {:.2f} + {:.5f} * 광고비".format(intercept, slope))
print("결정계수 (R²): {:.4f}".format(r2))
# 5. 예측 및 시각화
df['predicted_conversions'] = model.predict(X)
plt.scatter(df['ad_spend'], df['conversions'], color='blue', label='실제 전환수')
plt.plot(df['ad_spend'], df['predicted_conversions'], color='red', label='회귀 직선')
plt.title('광고비 대비 전환수 분석')
plt.xlabel('광고비 ($)')
plt.ylabel('전환수')
plt.legend()
plt.show()
▶ 분석 보고서




다중 선형 회귀와 모델 평가
1. 다중 선형 회귀 (Multiple Linear Regression)
하나의 종속 변수(타겟 변수)를 여러 개의 독립 변수(설명 변수)를 사용하여 예측하는 회귀 분석 기법

2. 모델 평가 지표
2.1 결정 계수 ( R^2, Coefficient of Determination)
모델이 실제 데이터를 얼마나 잘 설명하는지를 나타내는 지표
값의 범위: 0 ≤ R^2 ≤ 1
값이 1에 가까울수록 모델이 데이터를 잘 설명하는 것이며, 0에 가까울수록 설명력이 낮
2.2 평균 제곱 오차 (MSE, Mean Squared Error)
예측값과 실제값 간의 오차를 제곱하여 평균을 구한 값
값이 작을수록 모델의 예측 성능이 좋음을 의미
2.3 평균 절대 오차 (MAE, Mean Absolute Error)
예측값과 실제값 간의 절대 차이의 평균을 구한 값
2.4 평균 절대 백분율 오차 (MAPE, Mean Absolute Percentage Error)
예측값과 실제값 간의 차이를 백분율로 변환하여 평균을 구한 값
3. 다중 선형 회귀 모델의 가정
3.1 선형성 (Linearity)
독립 변수와 종속 변수 간의 관계가 선형이라는 가정
즉, 독립 변수가 증가하거나 감소할 때 종속 변수도 일정한 비율로 증가하거나 감소해야 함
선형성이 깨지면 모델이 올바르게 예측할 수 없음
3.2 독립성 (Independence)
독립 변수들끼리는 서로 상관관계가 없어야 함
독립 변수 간에 다중 공선성(Multicollinearity)이 있으면 회귀 모델의 신뢰성이 떨어짐
다중 공선성이 존재하면 특정 변수의 중요도를 해석하기 어려워
3.3 등분산성 (Homoscedasticity)
독립 변수의 값이 변화하더라도 오차(Residual)의 분산이 일정해야 함
만약 등분산성이 깨지면 모델의 예측 성능이 특정 구간에서만 좋고, 다른 구간에서는 나쁠 수 있음
이를 해결하기 위해 로그 변환, 정규화 등의 기법을 사용할 수 있음
3.4 정규성 (Normality)
회귀 모델의 오차(Residuals)는 정규 분포를 따라야 함
오차가 정규성을 가지면 회귀 계수의 신뢰 구간을 정확하게 계산할 수 있고, 모델의 예측이 안정적
정규성이 깨지면 t-검정이나 F-검정과 같은 통계적 검정이 잘못된 결론을 내릴 가능성이 높아짐

다중 선형 회귀와 모델 평가 : 그로스 마케팅(Growth Marketing) 예제
로지스틱 회귀(Logistic Regression) 개념과 활용
로지스틱 회귀는 이진 분류(Binary Classification) 문제를 해결하는 지도 학습(Supervised Learning) 알고리즘으로,
출력값이 확률(0~1 사이의 값)로 변환된 후 특정 임계값(threshold)에 따라 분류
1. 로지스틱 회귀 개념
- 선형 회귀와 달리 종속 변수( y )가 연속형이 아닌 이진 값(0 또는 1)을 가지는 경우 사용
- 선형 회귀와 달리, 예측값을 0~1 사이의 확률 값으로 변환하기 위해 시그모이드 함수(Sigmoid Function) 를 적용
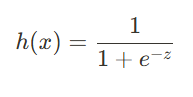
- z = B0 + B1 x1 + B2 x2 + ... + Bnxn (선형 결합)
- h(x) 값은 항상 0과 1 사이의 값(확률)
해석
- h(x) ≥0.5 이면 클래스 1
- $h(x) < 0.5 이면 클래스 0
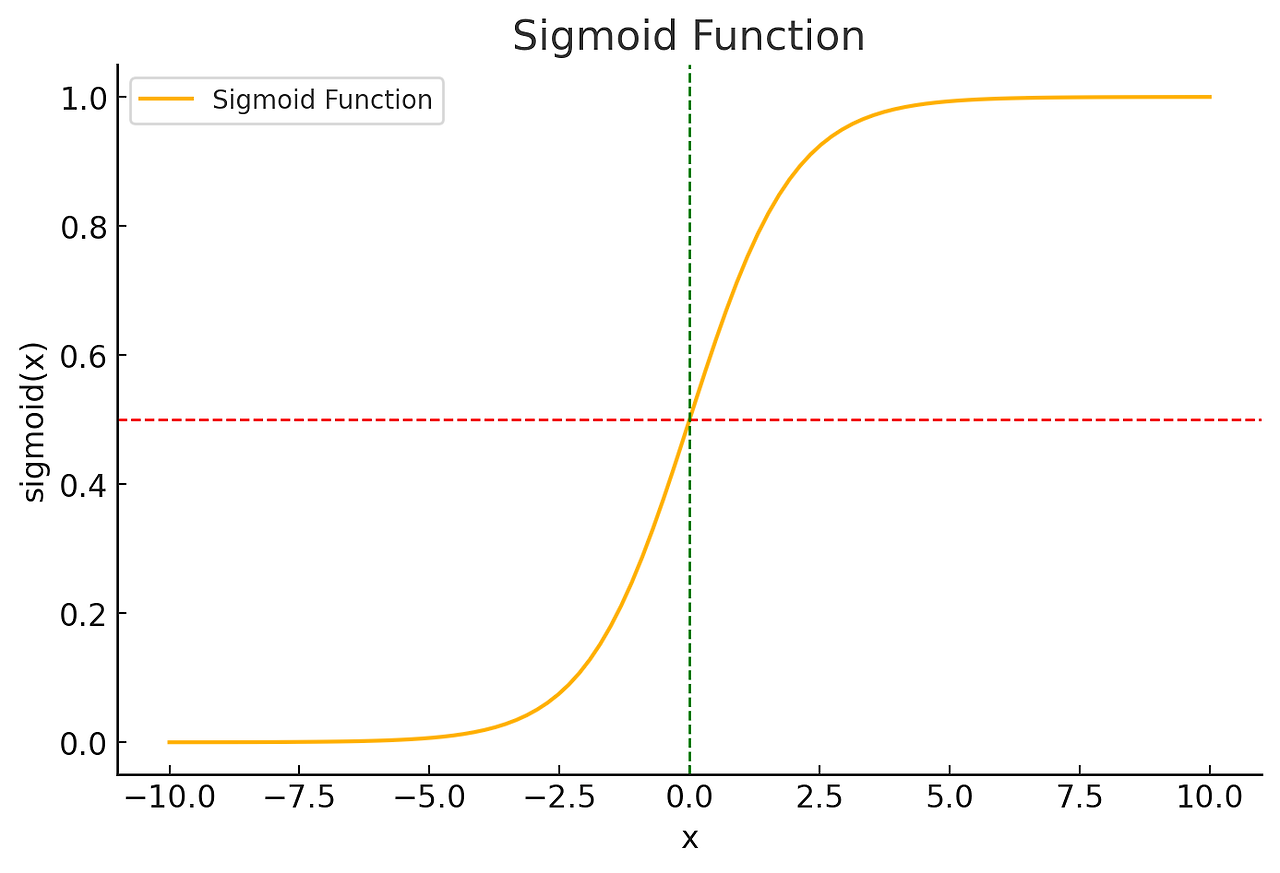
2. 로지스틱 회귀 연습
2.1 로지스틱 회귀 시각화 (시그모이드)
import numpy as np
import matplotlib.pyplot as plt
# 시그모이드 함수 정의
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# x 값 범위 설정
z = np.linspace(-10, 10, 100)
sigmoid_values = sigmoid(z)
# 그래프 출력
plt.figure(figsize=(8, 5))
plt.plot(z, sigmoid_values, label="Sigmoid Function")
plt.axvline(x=0, color='r', linestyle='dashed', label="Decision Boundary (z=0)")
plt.xlabel("z (Linear Combination)")
plt.ylabel("Sigmoid Output (Probability)")
plt.title("로지스틱 회귀 - 시그모이드 함수")
plt.legend()
plt.grid()
plt.show()
시그모이드 함수 특징
- z → - ∞ 일 때, h(x) → 0
- z → + ∞ 일 때, h(x) → 1
- z = 0 일 때, h(x) = 0.5
2.2 로지스틱 회귀 실습 코드
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 데이터 생성
np.random.seed(42)
n_samples = 200
watch_time = np.random.uniform(0, 10, n_samples) # 광고 시청 시간
visit_count = np.random.randint(1, 50, n_samples) # 방문 횟수
clicked = (watch_time * 0.3 + visit_count * 0.1 + np.random.normal(0, 1, n_samples) > 3.5).astype(int) # 클릭 여부 (0 or 1)
# 데이터프레임 생성
df = pd.DataFrame({"Watch Time": watch_time, "Visit Count": visit_count, "Clicked": clicked})
# 학습/테스트 데이터 분리
X = df[["Watch Time", "Visit Count"]]
y = df["Clicked"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측 및 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"정확도(Accuracy): {accuracy:.2f}")
print("혼동 행렬:\n", confusion_matrix(y_test, y_pred))
print("분류 보고서:\n", classification_report(y_test, y_pred))
3. 모델 평가
로지스틱 회귀 모델을 평가할 때 아래의 주요 지표를 사용
3.1 정확도 (Accuracy)

- 전체 샘플 중 올바르게 예측된 비율
- 데이터가 불균형할 경우 신뢰할 수 없음
3.2 정밀도 (Precision)
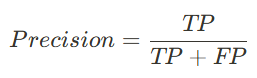
- 모델이 클래스 1(클릭됨) 이라고 예측한 것 중 실제 맞춘 비율
- FP(실제로는 클릭 안 했는데 클릭했다고 예측)를 줄이는 데 중요
3.3 재현율 (Recall)

- 실제로 클래스 1(클릭됨) 인 것 중 모델이 맞춘 비율
- FN(실제로 클릭했는데 클릭 안 했다고 예측)을 줄이는 데 중요
3.4 F1-Score
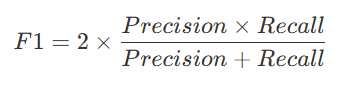
- Precision과 Recall의 조화 평균
- 불균형 데이터(Positive/Negative 비율이 차이가 클 때)에서 유용
▶Teachable Machine 을 이용해 모델 평가 연습 진행 (이부분이 메인은 아니라 흐름상 내용 생략합니다)
그로스마케팅 로지스틱회귀 예시
1. 고객 이탈 예측 (Customer Churn Prediction)
고객이 이탈할 가능성을 예측하는 모델을 구축한다. 이탈을 방지하고 고객 유지 전략을 개선하는 것이 목표이다.
문제 정의
- 독립 변수(X)
- 방문 빈도(Visits per Month): 한 달 동안 방문한 횟수
- 평균 구매 금액(Average Purchase Amount, $): 고객의 평균 결제 금액
- 고객 서비스 이용 횟수(Customer Support Calls): 고객이 서비스 센터에 문의한 횟수
- 할인 사용 여부(Used Discount, 0 or 1): 고객이 할인 쿠폰을 사용했는지 여부
- 종속 변수(y)
- 이탈 여부(Churn, 0 or 1): 고객이 다음 달에도 유지(0)될지, 이탈(1)할지
예제 데이터 파일
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 데이터 로드
df = pd.read_csv("customer_churn.csv")
# 독립 변수(X)와 종속 변수(y) 설정
X = df.drop(columns=["Churn"])
y = df["Churn"]
# 학습/테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측 및 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"정확도: {accuracy:.2f}")
print("분류 보고서:\n", classification_report(y_test, y_pred))
2. 광고 클릭 예측 (Ad Click Prediction)
광고 캠페인에서 고객이 광고를 클릭할 가능성을 예측하여 광고 전략을 최적화하는 것이 목표이다.
문제 정의
독립 변수(X)
- 광고 노출 횟수(Ad Impressions): 고객이 광고를 본 횟수
- 광고 시청 시간(Watch Time, sec): 광고를 시청한 시간(초)
- SNS 공유 여부(SNS Shared, 0 or 1): 광고가 SNS에서 공유되었는지 여부
- 광고 유형(Ad Type, 0=배너광고, 1=비디오광고): 광고 종류
- 종속 변수(y)
- 광고 클릭 여부(Clicked Ad, 0 or 1): 고객이 광고를 클릭했는지 여부
예제 데이터 파일
# 데이터 로드
df = pd.read_csv("ad_clicks.csv")
# 독립 변수(X)와 종속 변수(y) 설정
X = df.drop(columns=["Clicked Ad"])
y = df["Clicked Ad"]
# 학습/테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측 및 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"정확도: {accuracy:.2f}")
print("분류 보고서:\n", classification_report(y_test, y_pred))
3. 로지스틱 회귀를 활용한 고객 전환율 분석 보고서
예제 데이터 파일
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 데이터 로드
df = pd.read_csv("conversion_rate_analysis.csv")
# 데이터 분포 확인
plt.figure(figsize=(10, 6))
sns.histplot(df["Ad Spend ($)"], bins=30, kde=True, color='blue')
plt.title("광고 비용 분포")
plt.xlabel("Ad Spend ($)")
plt.ylabel("Frequency")
plt.show()
# 웹사이트 방문 수와 전환 여부 관계 시각화
plt.figure(figsize=(10, 6))
sns.boxplot(x="Converted", y="Website Visits", data=df)
plt.title("웹사이트 방문 수와 전환 여부 관계")
plt.xlabel("Converted (0=No, 1=Yes)")
plt.ylabel("Website Visits")
plt.show()
# 할인 제공 여부와 전환율 비교
plt.figure(figsize=(8, 5))
sns.barplot(x="Discount Offered", y="Converted", data=df)
plt.title("할인 제공 여부에 따른 전환율 비교")
plt.xlabel("Discount Offered (0=No, 1=Yes)")
plt.ylabel("Conversion Rate")
plt.show()
# 데이터셋 분리
X = df.drop(columns=["Converted"])
y = df["Converted"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측 및 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"모델 정확도: {accuracy:.2f}")
print("분류 보고서:\n", classification_report(y_test, y_pred))
# 혼동 행렬 시각화
plt.figure(figsize=(6, 4))
sns.heatmap(confusion_matrix(y_test, y_pred), annot=True, fmt='d', cmap='Blues')
plt.title("혼동 행렬")
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.show()
분석 보고서






"오늘의 회고"
내용도 너무 많고 실습도 많이 하고 보고서도 작성하고 하루가 어떻게 흘러갔는지 정신없이 지나갔다.
끝나고 나보니 머리가 멍하고 지친 상태가 됐다. 월요일이라 더 그런가...
아직은 내가 직접 코드를 짤 수 있을지 강의자료가 있어서 복붙을 하는건지 잘 모르겠다,,
조금 더 연습해보고 이해도 더 많이 해야 될 것 같고 코드 복붙이 아니라 직접 한번 짜보는 시간이 필요할 것 같다
월요일 .. 고생하셨어요 ,,!! 다들 이번주도 힘내봐요..!!