[DAY29] 멋쟁이사자처럼부트캠프 그로스마케팅_Today I Learned
오늘의 학습 내용
- 계절성을 고려한 회귀 분석
- 인공신경망의 기본 구조 & 역전파와 딥러닝 모델 학습
계절성을 고려한 회귀 분석 (Seasonal Regression Analysis)
회귀 분석은 종속 변수와 독립 변수 간의 관계를 분석하는 통계 기법
계절성을 고려한 회귀 분석은 시간 요소(예: 월, 분기, 연도 등)를 독립 변수로 추가하여 계절적 변동을 반영하는 방법
1. 방법
- 더미 변수(Dummy Variables) 추가 : 월별, 계절별 변화를 반영하기 위해 더미 변수를 생성
- 푸리에 변환(Fourier Transformation) : 계절적 패턴을 사인(Sine) 및 코사인(Cosine) 함수를 이용해 모델링. 이는 특정 주기성을 더 정확하게 반영할 수 있는 방법
- 이동 평균 또는 지수 평활법(Exponential Smoothing) : 계절성을 제거하거나 보정하는 방식으로 사용
- ARIMA 또는 SARIMA 모델 사용 : 시계열 데이터를 다룰 때 자주 사용되는 모델이며, 계절 조정이 포함된 SARIMA 모델은 계절성을 반영할 수 있음
2. 예시
2.1 계절성을 고려한 회귀 분석 수행 예제
▶예제 코드
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
# 데이터 생성 (12개월 주기의 계절성을 가진 시계열 데이터)
np.random.seed(42)
months = np.arange(1, 25) # 2년 (24개월) 데이터
seasonal_effect = 10 * np.sin(2 * np.pi * months / 12) # 계절성 반영 (사인 함수)
trend = 0.5 * months # 증가하는 추세
noise = np.random.normal(0, 3, size=len(months)) # 랜덤 노이즈 추가
y = 50 + trend + seasonal_effect + noise # 최종 데이터
# 데이터프레임 생성
df = pd.DataFrame({"Month": months, "Sales": y})
df["Month_sin"] = np.sin(2 * np.pi * df["Month"] / 12) # 계절성을 위한 사인 변환
df["Month_cos"] = np.cos(2 * np.pi * df["Month"] / 12) # 계절성을 위한 코사인 변환
# 독립 변수 설정 (추세 + 계절성 반영)
X = df[["Month", "Month_sin", "Month_cos"]]
X = sm.add_constant(X) # 상수 추가 (절편)
# 회귀 분석 수행
model = sm.OLS(df["Sales"], X).fit()
# 결과 출력
print(model.summary())
# 예측 값 계산
df["Predicted"] = model.predict(X)
# 시각화
plt.figure(figsize=(10, 5))
plt.plot(df["Month"], df["Sales"], label="Actual Sales", marker='o')
plt.plot(df["Month"], df["Predicted"], label="Predicted Sales", linestyle="dashed", color="red")
plt.xlabel("Month")
plt.ylabel("Sales")
plt.title("Seasonal Regression Analysis")
plt.legend()
plt.grid()
plt.show()
▶코드 결과

2.2 온라인 쇼핑몰 마케팅 전략 효과 분석
시나리오
한 온라인 쇼핑몰에서 마케팅 전략의 효과를 분석하려고 합니다.
● 주요 관심 대상: 월별 광고비, 프로모션 여부, 트래픽(방문자 수) 가 매출에 미치는 영향
● 계절성을 고려: 특정 계절(예: 연말, 여름 시즌)에 따른 매출 변동 반영
● 분석 목표: 광고비와 프로모션이 매출에 미치는 영향 분석 및 향후 매출 예측
▶데이터 생성
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, r2_score
# 데이터 생성 설정
np.random.seed(42)
months = np.arange(1, 25) # 2년(24개월) 데이터
seasonal_effect = 20 * np.sin(2 * np.pi * months / 12) # 계절성 반영 (사인 함수)
trend = 2 * months # 증가하는 추세
noise = np.random.normal(0, 5, size=len(months)) # 랜덤 노이즈 추가
# 광고비, 트래픽, 프로모션 여부 설정
ad_spend = np.random.randint(50, 150, size=len(months)) # 광고비 (랜덤)
traffic = np.random.randint(1000, 5000, size=len(months)) # 방문자 수 (랜덤)
promotion = np.random.choice([0, 1], size=len(months), p=[0.7, 0.3]) # 프로모션 여부 (30% 확률)
# 최종 매출 데이터 생성 (광고비, 트래픽, 프로모션이 영향을 미침)
sales = 200 + (0.8 * ad_spend) + (0.05 * traffic) + (50 * promotion) + trend + seasonal_effect + noise
# 데이터프레임 생성
df = pd.DataFrame({
"Month": months,
"Ad_Spend": ad_spend,
"Traffic": traffic,
"Promotion": promotion,
"Sales": sales
})
# 계절성 반영을 위한 사인 및 코사인 추가
df["Month_sin"] = np.sin(2 * np.pi * df["Month"] / 12)
df["Month_cos"] = np.cos(2 * np.pi * df["Month"] / 12)
# 데이터 확인 (상위 5개 행 출력)
print(df.head())
▶ 회귀 분석 및 예측 코드 (sklearn)
# 독립 변수 (계절성 반영)
X = df[["Ad_Spend", "Traffic", "Promotion", "Month_sin", "Month_cos"]]
y = df["Sales"]
# 모델 학습
model = LinearRegression()
model.fit(X, y)
# 예측 값 계산
df["Predicted_Sales"] = model.predict(X)
# 성능 평가
mae = mean_absolute_error(df["Sales"], df["Predicted_Sales"])
r2 = r2_score(df["Sales"], df["Predicted_Sales"])
print(f"Mean Absolute Error (MAE): {mae:.2f}")
print(f"R-squared (R²): {r2:.4f}")
# 결과 시각화
plt.figure(figsize=(10, 5))
plt.plot(df["Month"], df["Sales"], label="Actual Sales", marker='o')
plt.plot(df["Month"], df["Predicted_Sales"], label="Predicted Sales", linestyle="dashed", color="red")
plt.xlabel("Month")
plt.ylabel("Sales")
plt.title("Growth Marketing Regression Analysis (sklearn)")
plt.legend()
plt.grid()
plt.show()
▶ 코드 결과

2.3 그로스마케팅 전략이 월별 활성 사용자 수(MAU) 에 미친 영향 분석
시나리오
한 온라인 서비스 기업이 고객 유지율(리텐션)을 높이기 위해 다양한 그로스 마케팅 전략을 실행했습니다. 이 전략에는 개인화된 추천 시스템 도입, 이메일 캠페인, 앱 내 알림 등이 포함되었습니다. 이러한 전략이 월별 활성 사용자 수(MAU)에 어떤 영향을 미쳤는지 분석하고자 합니다.
▶ 데이터 생성
import numpy as np
import pandas as pd
# 데이터 생성 설정
np.random.seed(42)
months = np.arange(1, 13) # 12개월 데이터
base_users = 10000 # 기본 활성 사용자 수
# 마케팅 전략 효과 (가중치)
personalization_effect = 0.05 # 개인화 추천 시스템 도입 효과
email_campaign_effect = 0.03 # 이메일 캠페인 효과
in_app_notification_effect = 0.02 # 앱 내 알림 효과
# 각 전략의 실행 여부 (1: 실행, 0: 미실행)
personalization = np.array([0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]) # 3월부터 도입
email_campaign = np.array([0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1]) # 격월로 실행
in_app_notification = np.array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1]) # 5월부터 도입
# 월별 활성 사용자 수 계산
mau = base_users * (1 + personalization * personalization_effect +
email_campaign * email_campaign_effect +
in_app_notification * in_app_notification_effect)
# 노이즈 추가
noise = np.random.normal(0, 200, size=len(months))
mau = mau + noise
# 데이터프레임 생성
df = pd.DataFrame({
"Month": months,
"Personalization": personalization,
"Email_Campaign": email_campaign,
"In_App_Notification": in_app_notification,
"MAU": mau
})
# 데이터 확인
print(df)
▶ 회귀 분석 및 예측 코드
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, r2_score
import matplotlib.pyplot as plt
# 독립 변수 및 종속 변수 설정
X = df[["Personalization", "Email_Campaign", "In_App_Notification"]]
y = df["MAU"]
# 모델 학습
model = LinearRegression()
model.fit(X, y)
# 회귀 계수 출력
coefficients = pd.DataFrame({
"Feature": X.columns,
"Coefficient": model.coef_
})
print(coefficients)
# 예측 값 계산
df["Predicted_MAU"] = model.predict(X)
# 성능 평가
mae = mean_absolute_error(df["MAU"], df["Predicted_MAU"])
r2 = r2_score(df["MAU"], df["Predicted_MAU"])
print(f"Mean Absolute Error (MAE): {mae:.2f}")
print(f"R-squared (R²): {r2:.4f}")
# 결과 시각화
plt.figure(figsize=(10, 5))
plt.plot(df["Month"], df["MAU"], label="Actual MAU", marker='o')
plt.plot(df["Month"], df["Predicted_MAU"], label="Predicted MAU", linestyle="dashed", color="red")
plt.xlabel("Month")
plt.ylabel("Monthly Active Users (MAU)")
plt.title("Impact of Growth Marketing Strategies on MAU")
plt.legend()
plt.grid()
plt.show()
▶ 코드 결과

▶ 결과 해석
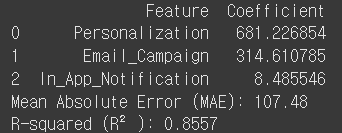
- 회귀 계수: 개인화 추천 시스템의 회귀 계수가 681이므로 이를 도입했을 때 평균적으로 MAU가 681명 증가함을 의미
- 모델 성능: R² 값이 0.86으로 모델이 실제 데이터를 잘 설명하고 있음을 의미. MAE는 예측 값과 실제 값의 평균 절대 오차를 나타내는 것으로 해당 모델에선 107.48로 107.48명 정도의 오차를 가짐.
2.4 쿠팡 e커머스 시장 전략 효과 분석
시나리오
쿠팡은 경쟁이 치열한 한국 e커머스 시장에서 신규 고객 유입을 극대화하기 위해 다양한 마케팅 전략을 실행하였습니다. 주요 전략은 다음과 같습니다.
할인 프로모션: 특정 상품군에 대해 5%에서 22%까지의 할인율을 적용하여 가격 경쟁력을 확보하였습니다.
무료 배송 서비스: 일정 금액 이상 구매 시 무료 배송을 제공하거나, 월 구독형 서비스인 '로켓와우' 멤버십을 통해 무료 배송 혜택을 제공하였습니다.
SNS 광고 캠페인: Facebook, Instagram, YouTube 등 다양한 SNS 플랫폼에서 적극적인 광고 캠페인을 전개하여 브랜드 인지도와 고객 유입을 증대시켰습니다.
목표: 이러한 마케팅 전략이 신규 고객 유입에 미치는 영향을 분석하고, 각 전략의 효과성을 정량적으로 평가하여 향후 마케팅 전략 수립에 활용하고자 합니다.
▶ 데이터 생성 (하드코딩된 실제 사례 기반 데이터)
import pandas as pd
# 하드코딩된 데이터 (2024년 1월 ~ 12월)
data = {
"Month": list(range(1, 13)),
"Discount_Rate": [5, 10, 7, 15, 12, 8, 20, 18, 22, 10, 12, 15], # 할인율(%)
"Free_Shipping": [0, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1], # 무료 배송 여부 (1: 제공, 0: 미제공)
"SNS_Ad_Spend": [200, 300, 250, 400, 350, 280, 500, 480, 550, 300, 350, 450], # SNS 광고비(단위: 만 원)
"New_Customers": [5300, 6700, 5800, 7800, 7200, 5900, 9200, 9100, 9800, 6500, 7000, 8300] # 신규 고객 수
}
# 데이터프레임 생성
df = pd.DataFrame(data)
# 데이터 확인
print(df)
▶ 회귀 분석 및 예측 코드
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, r2_score
import matplotlib.pyplot as plt
# 독립 변수 및 종속 변수 설정
X = df[["Discount_Rate", "Free_Shipping", "SNS_Ad_Spend"]]
y = df["New_Customers"]
# 모델 학습
model = LinearRegression()
model.fit(X, y)
# 회귀 계수 출력
coefficients = pd.DataFrame({
"Feature": X.columns,
"Coefficient": model.coef_
})
print(coefficients)
# 예측 값 계산
df["Predicted_New_Customers"] = model.predict(X)
# 성능 평가
mae = mean_absolute_error(df["New_Customers"], df["Predicted_New_Customers"])
r2 = r2_score(df["New_Customers"], df["Predicted_New_Customers"])
print(f"Mean Absolute Error (MAE): {mae:.2f}")
print(f"R-squared (R²): {r2:.4f}")
# 결과 시각화
plt.figure(figsize=(10, 5))
plt.plot(df["Month"], df["New_Customers"], label="Actual New Customers", marker='o')
plt.plot(df["Month"], df["Predicted_New_Customers"], label="Predicted New Customers", linestyle="dashed", color="red")
plt.xlabel("Month")
plt.ylabel("New Customers")
plt.title("Impact of Marketing Strategies on Customer Acquisition")
plt.legend()
plt.grid()
plt.show()
▶ 코드 결과

▶ 결과 해석

- 할인율이 1% 증가할 떄마다 신규 고객 수는 111명 증가로 할인률 증가가 신규 고객유입에 효과적일 것으로 보임
- 무료 배송을 제공한 달에 신규 고객수 평균 96명 감소로 무료 배송 제공이 신규 고객 유입에 효과적이지 않다고 판단 배송비 절감보다 다른 전략을 이용하는 것이 신규고객 유입에 있어 긍적적인 영향이 있을 것으로 보임
- SNS 광고비 1만원 증가 시 신규고객수 8명 증가로 광고비에 예산을 투자하는 것이 신규고객 유입에 효과가 있으나 미미한 편임
- R²값은 0.99로 모델이 전체 변동성을 매우 잘 설명하고 있음을 의미
- MAE 값은 100으로 예측과 실제 값 사이 100명 정도 차이가 있음을 의미
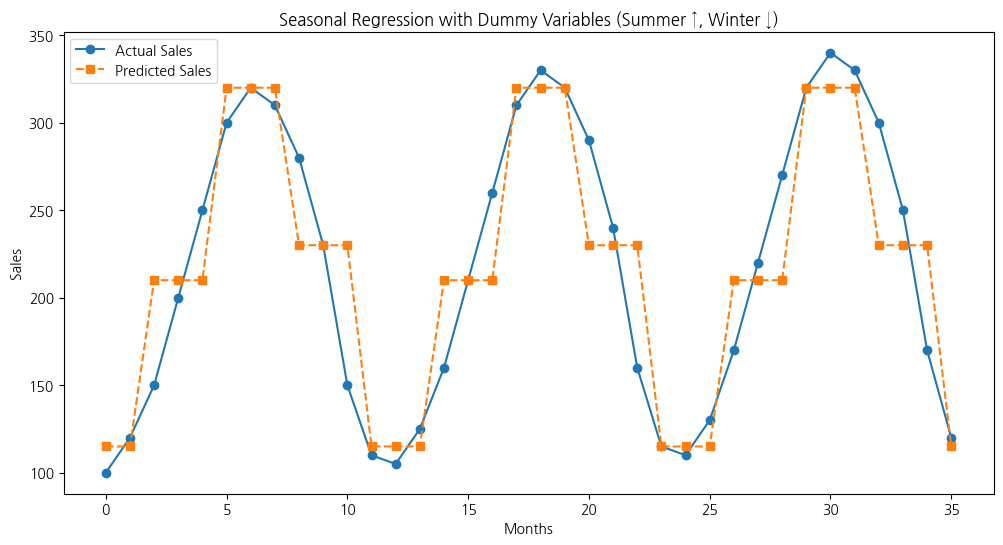
2.5 계절성을 고려한 예측 모델
시나리오
한 회사는 3년간(2019~2021년)의 월별 매출 데이터를 분석하여 계절성을 반영한 매출 예측 모델을 개발하고자 한다. 특정 월의 매출 패턴은 다음과 같다.
- 여름(6~8월): 매출 증가
- 겨울(12~2월): 매출 감소
- 봄(3,5월) 및 가을(9,11월) : 중간 수준
이를 기반으로 월별 계절성을 반영한 더미 변수를 생성하여 선형 회귀 모델을 학습하고, 향후 매출 예측에 활용할 수 있도록 한다.
▶ 코드 예제
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
# 3년간 월별 매출 데이터 (2019~2021)
data = {
'Year': [2019]*12 + [2020]*12 + [2021]*12, # 3년치 버퍼 생성
'Month': list(range(1, 13)) * 3,
'Sales': [
100, 120, 150, 200, 250, 300, 320, 310, 280, 230, 150, 110, # 2019년
105, 125, 160, 210, 260, 310, 330, 320, 290, 240, 160, 115, # 2020년
110, 130, 170, 220, 270, 320, 340, 330, 300, 250, 170, 120 # 2021년
]
}
df = pd.DataFrame(data)
# 계절 변수 추가
df['Season'] = df['Month'].apply(lambda x: 'Winter' if x in [12, 1, 2] else
'Spring' if x in [3, 4, 5] else
'Summer' if x in [6, 7, 8] else
'Fall')
# 계절을 더미 변수로 변환 (기준값: Winter)
df = pd.get_dummies(df, columns=['Season'], drop_first=True)
# 독립 변수 (X)와 종속 변수 (Y) 설정
X = df.drop(columns=['Sales', 'Year', 'Month']) # 'Month'는 제거
Y = df['Sales']
# 선형 회귀 모델 생성 및 학습
model = LinearRegression()
model.fit(X, Y)
# 예측
Y_pred = model.predict(X)
# 모델 평가
r2 = r2_score(Y, Y_pred)
print(f"R² Score: {r2:.4f}")
# 회귀 계수 출력
coefficients = pd.DataFrame({'Feature': X.columns, 'Coefficient': model.coef_})
print("\nRegression Coefficients:")
print(coefficients)
# 예측값 데이터프레임에 추가
df['Predicted_Sales'] = Y_pred
# 실제값과 예측값 시각화
plt.figure(figsize=(12, 6))
plt.plot(df.index, df['Sales'], label="Actual Sales", marker="o")
plt.plot(df.index, df['Predicted_Sales'], label="Predicted Sales", linestyle="--", marker="s")
plt.xlabel("Months")
plt.ylabel("Sales")
plt.title("Seasonal Regression with Dummy Variables (Summer ↑, Winter ↓)")
plt.legend()
plt.show()
# 전체 데이터 출력
print("\nData with Predictions:")
print(df.to_string(index=False))
▶ 코드 결과
인공신경망의 기본 구조 & 역전파와 딥러닝 모델 학습 설명
1. 인공신경망(Artificial Neural Network, ANN)의 기본 구조
인공신경망(ANN)은 인간의 신경망을 모방하여 만들어진 모델
- 입력층(Input Layer): 입력 데이터를 받아들이는 층
- 은닉층(Hidden Layer): 여러 개의 뉴런(Neuron)으로 구성되어 입력을 변환하는 층
- 출력층(Output Layer): 최종 예측 값을 출력하는 층
각 뉴런은 활성화 함수(Activation Function)를 통해 비선형성을 추가하여 학습 능력을 강화
2. 역전파(Backpropagation)
역전파는 신경망의 가중치를 업데이트하는 알고리즘으로, 오차를 최소화하기 위해 가중치를 조정하는 과정
2.1 역전파 과정
2.1.1 순전파(Forward Propagation)
- 입력 데이터를 각 층을 거쳐 출력층까지 전달
- 출력값을 계산하여 손실 함수(Loss Function)를 통해 오차를 계산
2.1.2 손실 계산(Loss Calculation)
- 예측값과 실제값의 차이를 계산하여 오차를 측정
- 예: 평균제곱오차(Mean Squared Error, MSE)
2.1.3 역전파(Backward Propagation)
- 손실을 기반으로 각 가중치에 대한 기울기(Gradient)를 계산
- 체인룰(Chain Rule)을 사용하여 미분을 수행하여 기울기(Gradient) 계산
2.1.4 가중치 업데이트(Weight Update)
- 경사 하강법(Gradient Descent)을 사용하여 가중치를 업데이트
- 가중치 업데이트:

3. 인공신경망 학습의 수식
3.1 순전파
● 가중치와 편향을 포함한 선형 변환

● 활성화 함수 적용

3.2 손실 함수(Loss Function)
손실 함수 L는 실제값 y와 예측값 hat{y}의 차이를 측정
(MSE: 평균제곱오차)

3.3 역전파(Backpropagation)

3.4 가중치 업데이트(Gradient Descent)
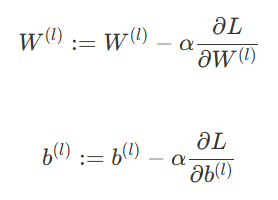
4. 인공신경망 학습
4.1 인공신경망 학습 코드 예제
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 데이터 생성 (XOR 문제를 확장한 예제)
np.random.seed(42)
X = np.random.rand(1000, 2) * 2 - 1 # [-1, 1] 범위의 랜덤 데이터
y = (X[:, 0] * X[:, 1] > 0).astype(int) # XOR 패턴
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터 정규화
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 인공신경망 모델 정의
# Dense 이므로 fully connected
# Dense() 안의 숫자는 뉴런의 개수
# relu 이용
# 층이 3개이므로 딥러닝
model = Sequential([
Dense(8, activation='relu', input_shape=(2,)), # 은닉층 1
Dense(8, activation='relu'), # 은닉층 2
Dense(1, activation='sigmoid') # 출력층 (이진 분류)
])
# 모델 컴파일 (손실 함수 & 최적화 알고리즘 정의)
# 최적화 알고리즘:adam, 손실함수: binary_crossentropy, 방법 : accuracy
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 모델 학습
# epoch : 1회 신경망 전체를 학습하는 것 (가중치 곱 다 한것) - epochs=100 : 신경망 전체 학습을 100번 반복
# batch_size : 한번에 읽어들이는 데이터 수
history = model.fit(X_train, y_train, epochs=100, batch_size=16, validation_data=(X_test, y_test))
# 모델 평가
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Test Accuracy: {accuracy:.4f}")
# 예측값 확인
predictions = (model.predict(X_test) > 0.5).astype(int)
print("\nPredictions:")
print(predictions[:10])모델 구조
입력층: 2개의 입력 뉴런
은닉층: 8개 뉴런 × 2개층 (ReLU 활성화 함수 사용)
출력층: 1개 뉴런 (Sigmoid 활성화 함수 사용)
손실 함수 & 최적화 기법
이진 분류 문제이므로 binary_crossentropy 사용
Adam 최적화(adam): 가중치 업데이트 자동 조정
모델 학습 과정(weight를 찾아가는 과정)
Epoch : 신경망 전체를 1회 학습
Epoch =100 신경망 전체 학습 100번 수행
batch_size : 한번에 학습하는 데이터 수
(예: 이미지 데이터 분석시 batch_size = 16 은 한번에 16개의 이미지를 학습함을 의미 )
학습 데이터(train)와 검증 데이터(test) 성능 비교
4.2 역전파 학습 진행 과정을 그래프로 표현하는 예시
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 데이터 생성 (XOR 패턴 확장)
np.random.seed(42)
X = np.random.rand(1000, 2) * 2 - 1 # [-1, 1] 범위의 랜덤 데이터
y = (X[:, 0] * X[:, 1] > 0).astype(int) # XOR 패턴
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터 정규화
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 인공신경망 모델 정의
model = Sequential([
Dense(8, activation='relu', input_shape=(2,)), # 은닉층 1
Dense(8, activation='relu'), # 은닉층 2
Dense(1, activation='sigmoid') # 출력층 (이진 분류)
])
# 모델 컴파일 (손실 함수 & 최적화 알고리즘 정의)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 모델 학습 (손실 및 정확도 기록)
history = model.fit(X_train, y_train, epochs=100, batch_size=16, validation_data=(X_test, y_test))
# 학습 과정 시각화
fig, ax1 = plt.subplots(figsize=(10, 5))
# 손실(loss) 그래프
ax1.plot(history.history['loss'], label='Training Loss', color='blue')
ax1.plot(history.history['val_loss'], label='Validation Loss', color='red', linestyle="--")
ax1.set_xlabel('Epochs')
ax1.set_ylabel('Loss')
ax1.set_title('Loss & Accuracy During Training')
ax1.legend(loc='upper right')
# 정확도(accuracy) 그래프 (y축 공유)
ax2 = ax1.twinx()
ax2.plot(history.history['accuracy'], label='Training Accuracy', color='green')
ax2.plot(history.history['val_accuracy'], label='Validation Accuracy', color='orange', linestyle="--")
ax2.set_ylabel('Accuracy')
ax2.legend(loc='lower right')
plt.show()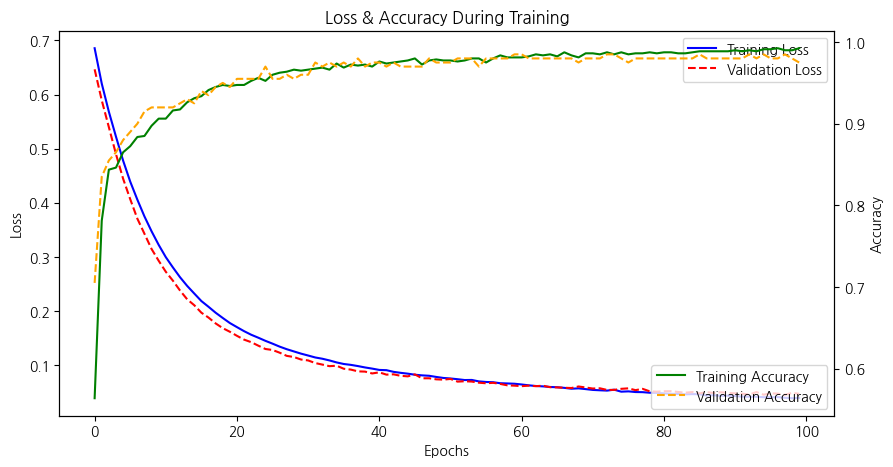
4.3 월별 활성 사용자 수(MAU) 분석
시나리오
한 온라인 서비스 기업이 고객 유지율(리텐션)을 높이기 위해 다양한 그로스 마케팅 전략을 실행했습니다. 이 전략에는 개인화된 추천 시스템 도입, 이메일 캠페인, 앱 내 알림 등이 포함되었습니다. 이러한 전략이 월별 활성 사용자 수(MAU)에 어떤 영향을 미쳤는지 분석하고자 합니다.
▶코드 예제
!pip install --upgrade keras tensorflowimport numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, BatchNormalization, Input
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error, r2_score
import matplotlib.pyplot as plt
# 데이터 생성
np.random.seed(42)
months = np.arange(1, 13) # 12개월 데이터
base_users = 10000
# 마케팅 전략 실행 여부
personalization = np.array([0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
email_campaign = np.array([0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1])
in_app_notification = np.array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1])
# 월별 MAU 계산
mau = base_users * (1 + personalization * 0.05 + email_campaign * 0.03 + in_app_notification * 0.02)
mau += np.random.normal(0, 200, size=len(months)) # 노이즈 추가
# 데이터프레임 생성
df = pd.DataFrame({
"Month": months,
"Personalization": personalization,
"Email_Campaign": email_campaign,
"In_App_Notification": in_app_notification,
"MAU": mau
})
# 독립 변수 및 종속 변수 설정
X = df[["Personalization", "Email_Campaign", "In_App_Notification"]]
y = df["MAU"]
# 데이터 정규화
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 모델 생성 (input_shape을 Input() 레이어로 변경)
model = Sequential()
model.add(Input(shape=(X_scaled.shape[1],)))
model.add(Dense(64, activation=tf.keras.activations.relu))
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(32, activation=tf.keras.activations.relu))
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(16, activation=tf.keras.activations.relu))
model.add(Dense(1)) # 출력층 (MAU 예측)
# 모델 컴파일
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
# 모델 학습
history = model.fit(X_scaled, y, epochs=2000, batch_size=4, validation_split=0.2, verbose=0)
# 예측 값 계산
y_pred = model.predict(X_scaled).flatten()
# 성능 평가
mae = mean_absolute_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"Mean Absolute Error (MAE): {mae:.2f}")
print(f"R-squared (R²): {r2:.4f}")
# 시각화
plt.figure(figsize=(10, 5))
plt.plot(df["Month"], df["MAU"], label="Actual MAU", marker='o')
plt.plot(df["Month"], y_pred, label="Predicted MAU", linestyle="dashed", color="red")
plt.xlabel("Month")
plt.ylabel("Monthly Active Users (MAU)")
plt.title("Impact of Growth Marketing Strategies on MAU (DNN Model)")
plt.legend()
plt.grid()
plt.show()
▶ 최적의 파라미터 찾기
| epochs=200 R²: -1018.4919 |
 |
| epochs=2000 R²: 0.0155 |
 |
| epochs=6000 R²: -4.4946 |
 |
| epochs=20000 R²: 0.0124 |
 |
시도해본 것 중 가장 모델 설명력이 우수한 것 : epochs=2000
" 오늘의 회고 "
오늘은 회귀분석 복습을 했는데 계절성을 고려하는 개념을 추가해서 진행했다.
더미변수를 활용해서 회귀분석을 했는데 사실 더미 변수의 개념이 아직은 완벽히 이해가 가진 않는 것 같다.
내가 실습한 내용이 맞는지도 잘 모르겠고 같은 훈련생들 답도 다 다르고 조금 혼란스러운 시간이었다.
이 외에는 딥러닝 실습을 진행했는데 학습시간이 오래걸리는 것이 단점이지만 직접 최적의 파라미터를 찾아나가는 과정은 재미있는것 같다, 그리고 오늘도 꼼꼼히 개념 설명을 해주신 덕분에 SLP MLP DNN 의 개념은 이제 설명할 수 있을 정도의 숙지가 된 것 같아 기분이 좋았다.
유난히 하루가 빨리 간 기분인데 다들 고생하셨습니다!