[DAY26] 멋쟁이사자처럼부트캠프 그로스마케팅_Today I Learned
오늘의 학습 내용
- KNN 알고리즘
- SVM
- 분류 모델 - 로지스틱 회귀 개념과 활용
- 분류 모델 - 모델 성능 평가와 다중 분류
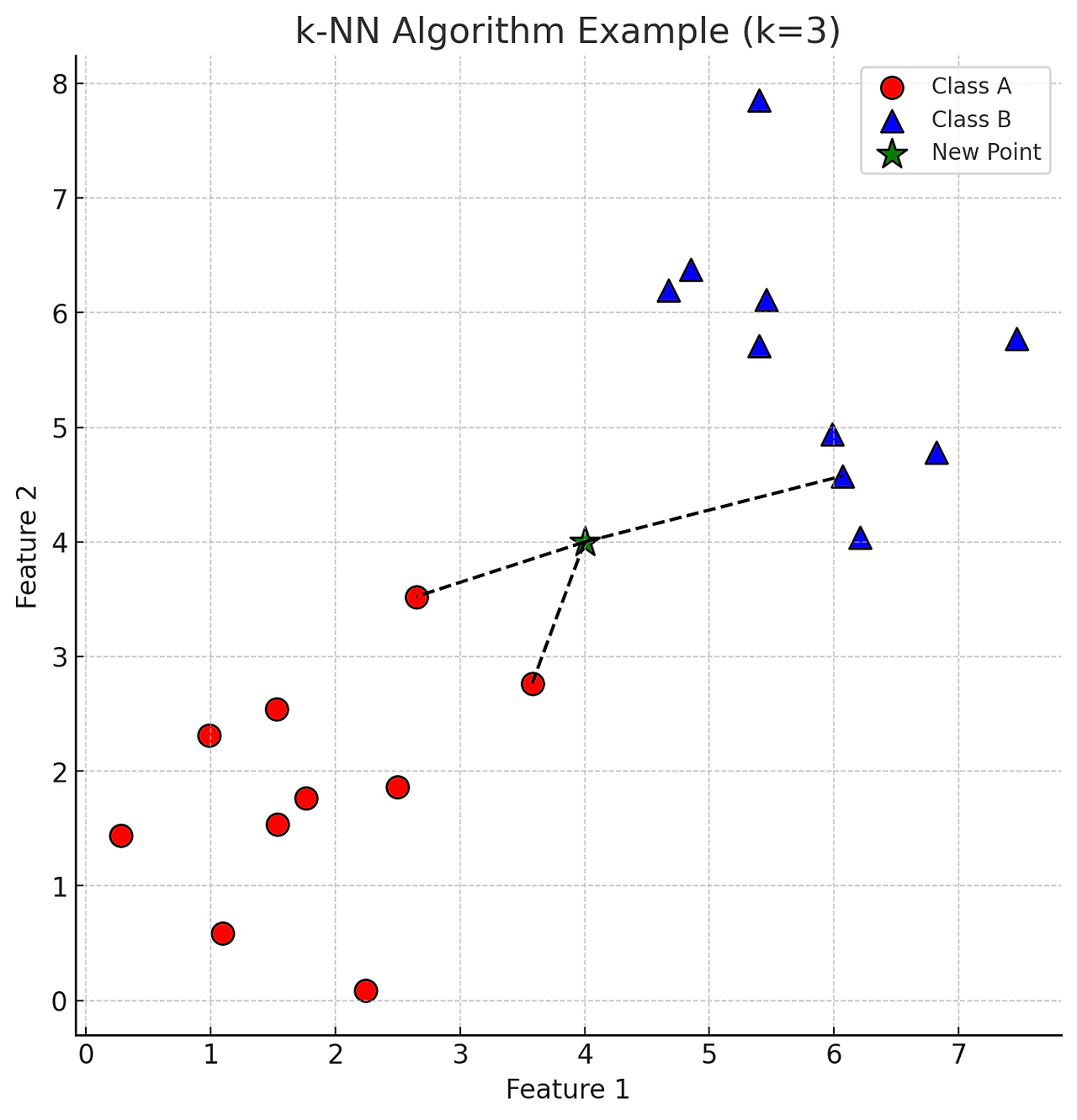
k-NN 알고리즘
1. 개요
1.1 거리 측정: 새로운 데이터 포인트와 모든 훈련 데이터 포인트 간의 거리를 계산. 일반적으로 유클리드 거리(Euclidean Distance)를 사용하지만, 맨해튼 거리(Manhattan Distance) 등 다른 거리 측정 방법도 사용 가능
1.2 이웃 선택: 계산된 거리 값을 기준으로 가장 가까운 k개의 이웃을 선택
1.3 분류/회귀:
- 분류: 선택된 k개의 이웃 중 가장 많은 클래스를 새로운 데이터 포인트의 클래스로 할당. 즉, 다수결 투표(Majority Voting) 방식으로 클래스를 결정
- 회귀: 선택된 k개의 이웃의 평균 값을 새로운 데이터 포인트의 예측 값으로 사용

2. k-NN 알고리즘 수식 표현
2.1 유클리드 거리 계산
- 두 점 A(x1, y1)와 B(x2, y2) 사이의 유클리드 거리

- 더 일반적으로, 두 n-차원 벡터 x = (x1, x2, · · · ,xn) 와 y = (y1, y2, · · · , yn) 사이의 유클리드 거리

2.2 k-NN 분류
- 새로운 데이터 포인트 x'가 주어졌을 때, 그 점과 가장 가까운 k개의 이웃을 찾음
- 각 이웃의 클래스를 확인하고, 가장 많이 나타나는 클래스를 x'의 클래스로 할당
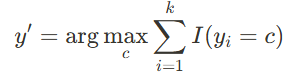
I 는 지시 함수로, yi 가 클래스 c 와 동일할 경우 1을, 그렇지 않으면 0을 반환
2.3 k-NN 회귀
- 새로운 데이터 포인트 x'의 예측 값은 가장 가까운 k개의 이웃의 출력 값의 평균으로 계산

3. k-NN 알고리즘의 주요 특징
장점:
- 이해하고 구현하기 쉬움
- 새로운 데이터에 대해 학습이 필요 없이 바로 예측 가능
단점:
- 데이터 포인트가 많아지면 계산량이 급격히 증가
- 데이터의 차원이 높아지면(즉, 특징이 많아지면) 성능이 저하될 수 있음( 차원의 저주(Curse of Dimensionality))
4. k-NN 알고리즘 예시
4.1 청소년의 구매 패턴에 따른 추천 패턴 예측
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 1. 가상 한국 청소년 의류 구매 패턴 데이터 생성 및 추천 정보 포함
def generate_korean_teen_fashion_data_with_recommendations():
# 데이터 생성
data = {
'Teenager': ['Teen1', 'Teen2', 'Teen3', 'Teen4', 'Teen5', 'Teen6', 'Teen7', 'Teen8', 'Teen9', 'Teen10'],
'Sportswear': [5, 3, 2, 4, 5, 2, 3, 4, 5, 1],
'Casual': [3, 4, 5, 3, 2, 4, 3, 4, 2, 5],
'Luxury': [2, 5, 4, 2, 3, 5, 2, 1, 3, 4],
'Streetwear': [4, 2, 5, 4, 3, 1, 4, 5, 2, 3],
'Fashionable': [5, 4, 3, 5, 4, 3, 2, 5, 4, 3],
'Average_Spending': [100000, 150000, 80000, 95000, 120000, 60000, 110000, 140000, 130000, 90000] # 원 단위
}
df = pd.DataFrame(data)
# 추천 정보 추가
recommendations = {
'Teen1': {'Brand': 'Nike', 'Category': 'Sportswear', 'Spending': 100000},
'Teen2': {'Brand': 'Adidas', 'Category': 'Casual', 'Spending': 150000},
'Teen3': {'Brand': 'Gucci', 'Category': 'Luxury', 'Spending': 80000},
'Teen4': {'Brand': 'Supreme', 'Category': 'Streetwear', 'Spending': 95000},
'Teen5': {'Brand': 'Zara', 'Category': 'Fashionable', 'Spending': 120000},
'Teen6': {'Brand': 'Uniqlo', 'Category': 'Casual', 'Spending': 60000},
'Teen7': {'Brand': 'Puma', 'Category': 'Sportswear', 'Spending': 110000},
'Teen8': {'Brand': 'H&M', 'Category': 'Fashionable', 'Spending': 140000},
'Teen9': {'Brand': 'Adidas', 'Category': 'Casual', 'Spending': 130000},
'Teen10': {'Brand': 'Nike', 'Category': 'Sportswear', 'Spending': 90000}
}
return df, recommendations
# 2. 데이터 로드 및 분할
df, brand_recommendations = generate_korean_teen_fashion_data_with_recommendations()
X = df[['Sportswear', 'Casual', 'Luxury', 'Streetwear', 'Fashionable', 'Average_Spending']]
y = df['Teenager']
# 3. K-NN 모델 학습
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X, y)
# 4. 새로운 청소년 구매 패턴 데이터
new_teen = pd.DataFrame({
'Sportswear': [1],
'Casual': [5],
'Luxury': [2],
'Streetwear': [5],
'Fashionable': [3],
'Average_Spending': [50000] # 원 단위로 예상되는 지출 금액
})
# 5. 새로운 청소년의 구매 패턴에 따른 추천 패턴 예측
predicted_teen = knn.predict(new_teen)[0]
print(f"Predicted Teenager Similarity: {predicted_teen}")
# 6. 예측된 청소년 패턴에 따른 추천 브랜드, 카테고리 및 사용 금액
recommendation = brand_recommendations.get(predicted_teen, None)
# 올바른 형태의 데이터로 접근할 수 있도록 수정
if isinstance(recommendation, dict):
print(f"Recommended Brand: {recommendation['Brand']}")
print(f"Recommended Category: {recommendation['Category']}")
print(f"Expected Spending: {recommendation['Spending']} 원")
else:
print("No recommendation available.")

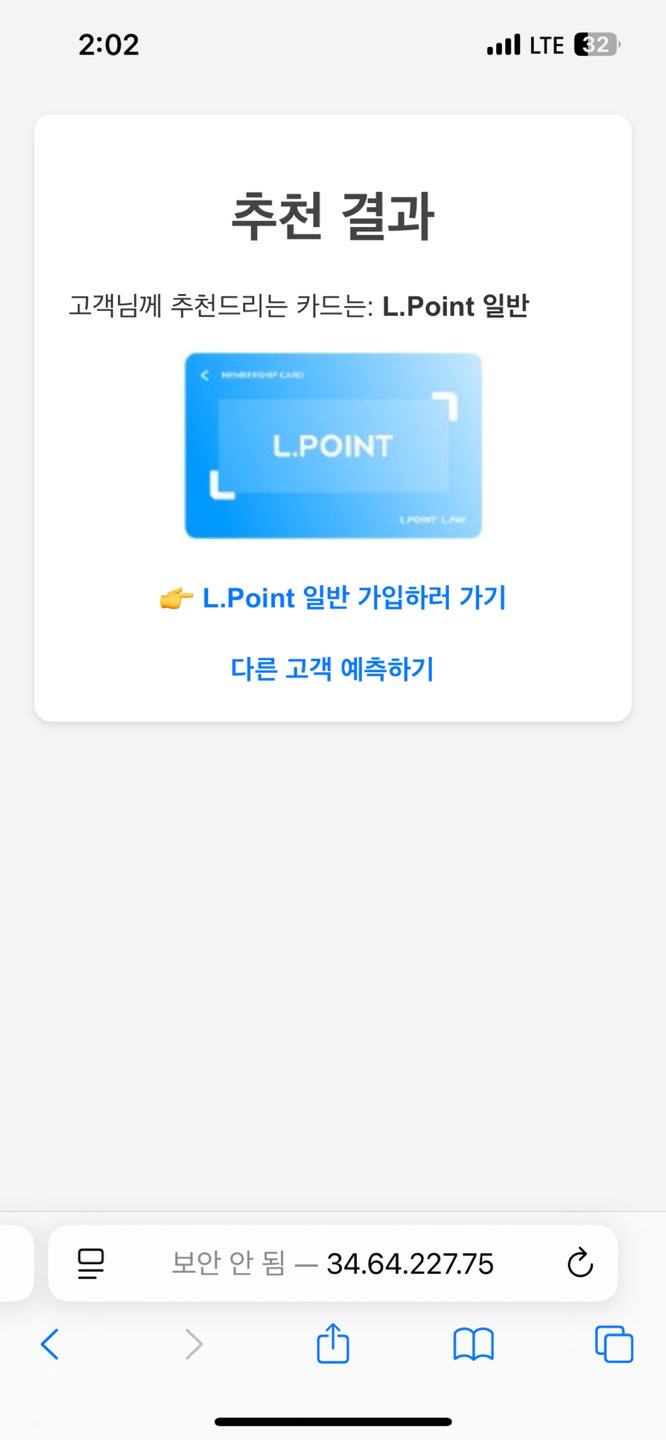
4.2 롯데 맴버스 고객 패턴 부선을 통한 카드 추천 웹서버 구축
▶가상 데이터

▶디렉토리 설정
members
├── app.py
├── members.csv
├── templates/
│ ├── index.html
│ └── result.html
└── static/
└── images/
├── L.point 일반.jpg
├── 롯데 트레블 카드.jpg
└── ... (이미지 데이터셋)▶app.py
▶templates/
▶결과
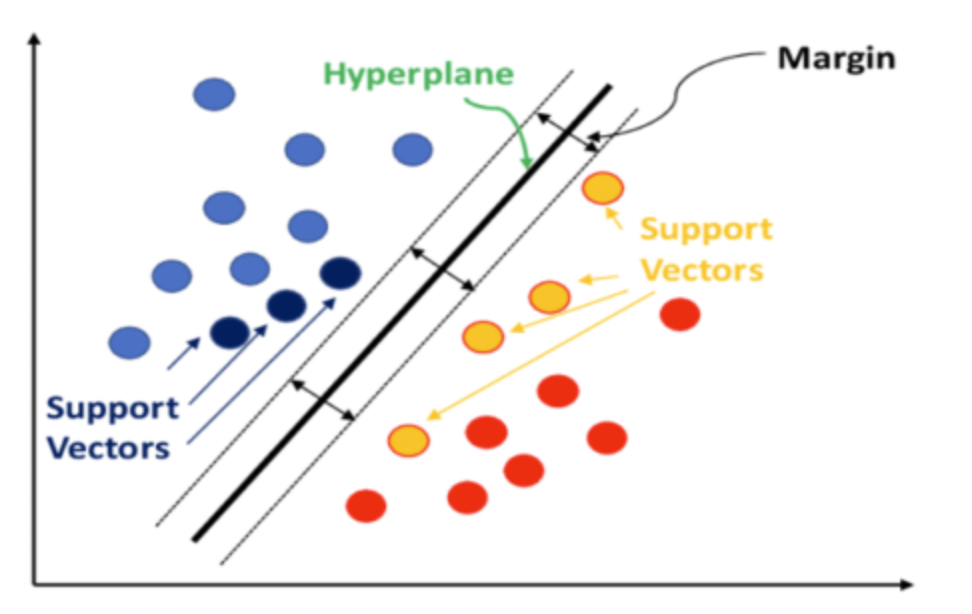
서포트 벡터 머신(SVM)
서포트 벡터 머신(SVM, Support Vector Machines)은 지도학습의 한 방법으로, 주로 분류(Classification)와 회귀(Regression) 문제에 사용되며 SVM은 주어진 데이터를 기반으로 최적의 초평면(Hyperplane)을 찾아, 새로운 데이터 포인트를 분류하거나 예측하는 역할

1. SVM의 개념
SVM은 주어진 데이터에서 두 클래스를 구분하는 최적의 초평면을 찾음.
이때, 각 클래스의 가장 가까운 데이터 포인트(즉, 서포트 벡터)와 초평면 사이의 거리를 최대화하는 것을 목표로 함
- 초평면(Hyperplane): 데이터를 분류하는 데 사용되는 경계
- 마진(Margin): 각 클래스의 서포트 벡터와 초평면 사이의 거리. SVM은 이 마진을 최대화하는 초평면을 찾음
- 서포트 벡터(Support Vectors): 각 클래스에서 초평면에 가장 가까운 데이터 포인트들. 이 서포트 벡터는 최적의 초평면을 정의하는 데 중요한 역할을 함
2. 지도학습에서의 사용
SVM은 지도학습(Supervised Learning)의 대표적인 분류 알고리즘으로, 라벨이 포함된 데이터를 학습하여 새로운 데이터의 라벨을 예측. 지도학습에서 SVM은 특히 이진 분류 문제에서 높은 성능을 보임
3. SVM의 수식 표현

4. SVM의 목적
서포트 벡터와 초평면 사이의 거리(Margin)를 최대화하는 w와 b를 찾는 것
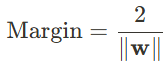
마진을 최대화하는 것은 w를 최소화하는 것과 같음
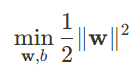
이 조건은 모든 i에 대해 다음과 같이 주어짐

여기서 yi는 각 데이터 포인트 xi의 실제 라벨(1 또는 -1)을 나타

SVM 커널
SVM 커널은 입력 데이터를 더 높은 차원의 공간으로 변환하는 수학적 함수
데이터가 원래 공간에서 선형적으로 구분되지 않을 때,
커널 트릭(kernel trick)을 사용하면 데이터를 새로운 공간으로 매핑하여 선형적으로 구분
1. SVM 커널의 종류
1.1 선형 커널 (Linear Kernel)
- 수식: K(xi, xj) = xi ^ T xj
- 데이터가 거의 선형적으로 구분되는 경우에 사용되며, 다른 커널보다 계산 비용이 적음
1.2 다항 커널 (Polynomial Kernel)
- 수식: K(xi, xj) = (xi^T xj + c)^d
- 매개변수:
- d : 다항식의 차수.
- c : 상수
- 특징 간의 상호작용이 중요한 경우에 사용됩니다. 예를 들어, 자연어 처리(NLP) 작업에서 유용
1.3 RBF 커널 (Radial Basis Function Kernel) 또는 가우시안 커널
- 수식: K(xi, xj) = exp(-gamma |xi - xj|^2)
- 매개변수: gamma, 이 값은 하나의 훈련 예제가 미치는 영향을 정의, 낮은 gamma는 더 넓은 범위를, 높은 gamma는 더 좁은 범위를 의미
- 복잡한 비선형 경계를 처리할 수 있어 가장 널리 사용되는 커널
1.4 시그모이드 커널 (Sigmoid Kernel)
- 수식: K(xi, xj) = tanh( alpha xi^T xj + c)
- 매개변수:
- alpha : 스케일링 매개변수.
- c : 상수.
- 신경망과 유사하게 동작하지만, 특수한 작업에만 사용
SVM 실습 예제 : 개와 고양이 학습해 분류
▶ 예제 데이터
▶ 코드 예제
import cv2
import numpy as np
import os
from sklearn import svm
from sklearn.metrics import accuracy_score, roc_curve, roc_auc_score
from sklearn.model_selection import train_test_split
from skimage.feature import hog
import matplotlib.pyplot as plt
# 1. HOG 특징 추출 함수
def extract_hog_features(image):
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 흑백 변환
hog_features, _ = hog(gray_image, pixels_per_cell=(8, 8),
cells_per_block=(2, 2), block_norm='L2-Hys', visualize=True)
return hog_features
# 2. 고양이(cat)와 개(dog) 데이터 로드
def load_images_from_folders(cat_folder, dog_folder):
images = [] # 이미지 데이터 저장할 리스트
labels = [] # 이미지 라벨 저장할 리스트
# 고양이 이미지 로드
for filename in os.listdir(cat_folder):
img_path = os.path.join(cat_folder, filename)
img = cv2.imread(img_path)
if img is None:
print(f"Warning: Unable to read {filename}")
continue
img = cv2.resize(img, (64, 64))
features = extract_hog_features(img)
if features.shape[0] != 1764: # HOG 벡터 크기 체크
print(f"Error: Unexpected HOG feature size {features.shape} for {filename}")
continue
images.append(features)
labels.append(0) # 고양이 = 0
# 개 이미지 로드
for filename in os.listdir(dog_folder):
img_path = os.path.join(dog_folder, filename)
img = cv2.imread(img_path)
if img is None:
print(f"Warning: Unable to read {filename}")
continue
img = cv2.resize(img, (64, 64))
features = extract_hog_features(img)
if features.shape[0] != 1764:
print(f"Error: Unexpected HOG feature size {features.shape} for {filename}")
continue
images.append(features)
labels.append(1) # 개 = 1
if len(images) == 0:
raise ValueError("Error: No valid images found in the folders.")
return np.array(images), np.array(labels)
# 3. 데이터 로드 (cat과 dog 경로 분리)
cat_folder_path = '/content/data/cat' # 고양이 데이터 경로
dog_folder_path = '/content/data/dog' # 개 데이터 경로
X, y = load_images_from_folders(cat_folder_path, dog_folder_path)
# 4. 데이터 확인 (정확도 0% 방지)
print(f"Total samples: {len(X)}, Labels: {len(y)}")
if X.shape[0] == 0:
raise ValueError("No images found. Please check the dataset path.")
# 5. 데이터셋 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 6. SVM 모델 학습
model = svm.SVC(kernel='linear')
model.fit(X_train, y_train)
# 7. 예측 및 정확도 평가
y_pred = model.predict(X_test)
print(f'Accuracy: {accuracy_score(y_test, y_pred) * 100:.2f}%')
# 8. 테스트 이미지 예측 및 시각화
def predict_image(img_path):
img = cv2.imread(img_path)
if img is None:
print(f"Error: Unable to read image {img_path}")
return
img_resized = cv2.resize(img, (64, 64))
features = extract_hog_features(img_resized)
features = features.reshape(1, -1)
prediction = model.predict(features)
if prediction == 0:
print("It's a cat!")
else:
print("It's a dog!")
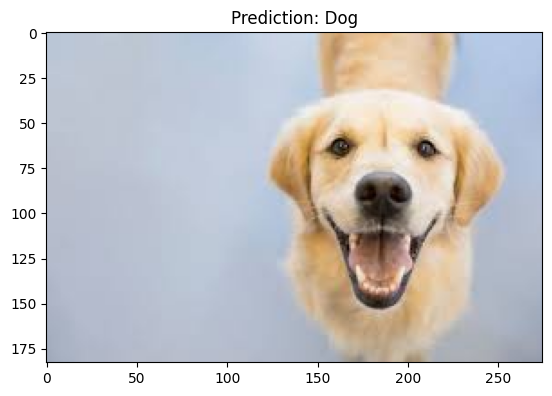
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.title("Prediction: Cat" if prediction == 0 else "Prediction: Dog")
plt.show()
# 9. 예측 예시
predict_image('/content/data/dog/dog.jpeg')
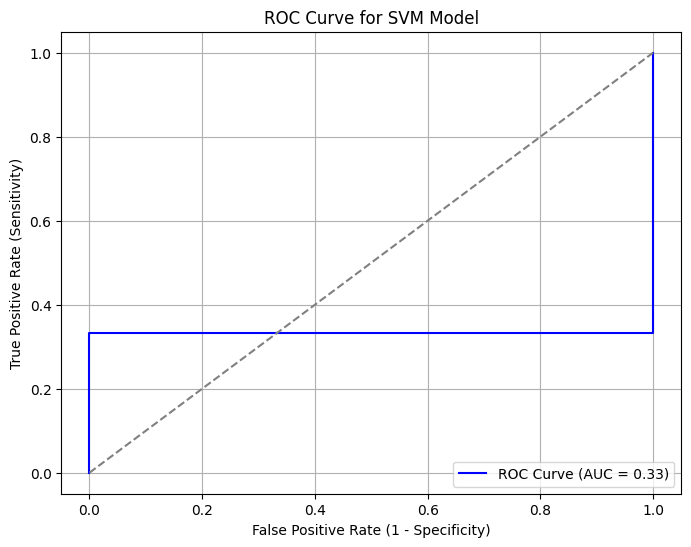
#예측 확률 계산
y_scores = model.decision_function(X_test)
# ROC 곡선 데이터 계산
fpr, tpr, _ = roc_curve(y_test, y_scores)
# AUC 값 계산
auc_score = roc_auc_score(y_test, y_scores)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='blue', label=f'ROC Curve (AUC = {auc_score:.2f})')
plt.plot([0, 1], [0, 1], color='gray', linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve for SVM Model')
plt.legend()
plt.grid()
plt.show()
▶ 결과
비즈니스 시나리오
1. 광고 캠페인 전환율 예측
시나리오
A사의 마케팅팀은 신규 온라인 광고 캠페인을 실행하고 있으며, 특정 고객이 광고를 본 후 실제 구매(전환)를 할 가능성이 높은지를 예측하고 싶다. 이를 통해 광고 예산을 최적화하고, 전환 가능성이 높은 고객에게 더 많은 마케팅 자원을 집중할 수 있다.
▶ 목표
- 고객의 인구통계 및 행동 데이터를 기반으로 전환(구매) 여부를 예측
- 로지스틱 회귀를 활용하여 고객이 전환할 확률을 계산
- 예측 결과를 기반으로 맞춤형 마케팅 전략 수립
▶ 데이터 생성
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, roc_auc_score, confusion_matrix
# 가상의 고객 데이터 생성
data = {
'age': [22, 45, 25, 33, 50, 41, 29, 39, 48, 23, 31, 36, 27, 40, 53, 44, 26, 38, 51, 30],
'income': [3000, 6000, 3200, 5000, 7200, 6500, 4000, 5800, 7000, 3100,
4800, 5500, 3900, 6200, 7500, 6700, 3500, 5600, 7100, 4200],
'browsing_time': [5, 15, 7, 10, 20, 13, 8, 12, 18, 6, 9, 11, 8, 14, 21, 17, 7, 11, 19, 10],
'num_clicks': [1, 5, 2, 3, 6, 4, 2, 3, 5, 1, 3, 4, 2, 4, 6, 5, 2, 3, 5, 2],
'ad_exposure': [2, 6, 3, 5, 8, 7, 4, 6, 8, 3, 5, 6, 4, 7, 9, 7, 4, 6, 8, 5],
'converted': [0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0]
}
df = pd.DataFrame(data)
# 데이터 분할 (독립변수 X, 종속변수 y)
X = df[['age', 'income', 'browsing_time', 'num_clicks', 'ad_exposure']]
y = df['converted']
# 훈련 데이터와 테스트 데이터로 분할 (80% 훈련, 20% 테스트)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터 정규화 (로지스틱 회귀는 입력 스케일에 민감)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
▶ 로지스틱 회귀 모델 훈련 및 평가
# 로지스틱 회귀 모델 생성
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측 수행
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1]
# 성능 평가
accuracy = accuracy_score(y_test, y_pred)
auc_score = roc_auc_score(y_test, y_pred_proba)
conf_matrix = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)
# 결과 출력
print(f"모델 정확도: {accuracy:.2f}")
print(f"AUC 점수: {auc_score:.2f}")
print("혼동 행렬:")
print(conf_matrix)
print("분류 보고서:")
print(report)
▶ ROC 커브 시각화
from sklearn.metrics import roc_curve
# ROC 곡선 계산
fpr, tpr, _ = roc_curve(y_test, y_pred_proba)
# 그래프 그리기
plt.figure(figsize=(6, 6))
plt.plot(fpr, tpr, color='blue', label='ROC Curve (AUC = {:.2f})'.format(auc_score))
plt.plot([0, 1], [0, 1], linestyle='--', color='gray')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend()
plt.show()
▶ 결과
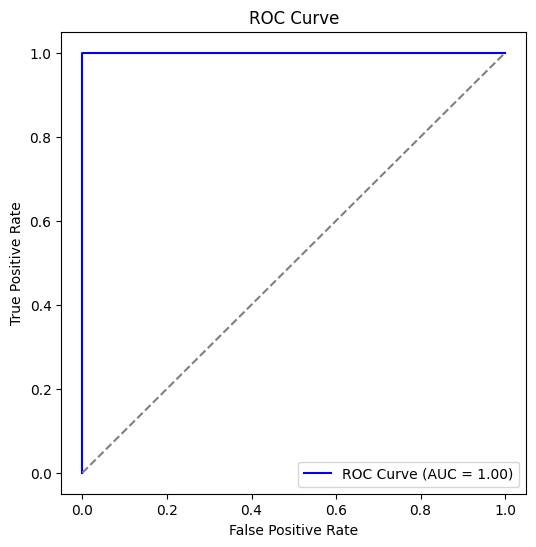
▶ 비즈니스 인사이트
- 간(browsing_time)이 구매 전환율에 영향을 크게 미칠 가능성이 있음.
- 소득(income)도 중요한 역할을 할 수 있으며, 특정 소득 구간에서 전환율이 더 높을 수 있음.
- 이 모델을 활용하여 전환 가능성이 높은 고객에게 리타겟팅 광고를 집중적으로 집행하거나, 전환 가능성이 낮은 고객군에 대한 맞춤형 프로모션 전략을 세울 수 있음.
2. 이메일 마케팅 캠페인의 반응 예측
B사는 이메일 마케팅을 통해 고객들에게 새로운 프로모션을 안내하고 있다. 하지만 모든 고객이 이메일을 열어보거나 클릭하는 것은 아니다. 이에 따라 특정 고객이 이메일을 열어볼 가능성이 높은지를 예측하는 모델을 구축하여, 반응 가능성이 높은 고객에게 더 많은 마케팅 자원을 집중하고, 낮은 고객에게는 다른 접근 방식을 시도하려 한다.
▶ 목표
- 고객의 과거 이메일 반응 및 인구통계 데이터를 바탕으로 이메일 오픈 가능성을 예측
- 로지스틱 회귀를 활용하여 이메일 오픈 확률을 계산
- 타겟 마케팅 전략을 개선하여 효과적인 이메일 캠페인 실행
▶ 데이터 생성
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, roc_auc_score, confusion_matrix
# 가상의 이메일 마케팅 데이터 생성
data = {
'age': [22, 45, 25, 33, 50, 41, 29, 39, 48, 23, 31, 36, 27, 40, 53, 44, 26, 38, 51, 30],
'num_emails_received': [5, 15, 8, 12, 18, 13, 9, 14, 20, 6,
10, 13, 7, 15, 21, 17, 8, 12, 19, 11],
'avg_response_time': [30, 12, 45, 20, 5, 10, 35, 18, 7, 40,
22, 16, 38, 14, 4, 9, 32, 19, 6, 28],
'num_purchases': [1, 3, 0, 2, 4, 2, 1, 3, 4, 0, 2, 3, 1, 3, 5, 4, 1, 2, 4, 2],
'past_open_rate': [0.2, 0.8, 0.1, 0.6, 0.9, 0.7, 0.3, 0.65, 0.85, 0.15,
0.5, 0.68, 0.25, 0.72, 0.92, 0.78, 0.22, 0.6, 0.88, 0.4],
'opened_email': [0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0]
}
df = pd.DataFrame(data)
# 데이터 분할 (독립변수 X, 종속변수 y)
X = df[['age', 'num_emails_received', 'avg_response_time', 'num_purchases', 'past_open_rate']]
y = df['opened_email']
# 훈련 데이터와 테스트 데이터로 분할 (80% 훈련, 20% 테스트)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터 정규화 (로지스틱 회귀는 입력 스케일에 민감)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
▶ 로지스틱 회귀 모델 훈련 및 평가
# 로지스틱 회귀 모델 생성
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측 수행
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1]
# 성능 평가
accuracy = accuracy_score(y_test, y_pred)
auc_score = roc_auc_score(y_test, y_pred_proba)
conf_matrix = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)
# 결과 출력
print(f"모델 정확도: {accuracy:.2f}")
print(f"AUC 점수: {auc_score:.2f}")
print("혼동 행렬:")
print(conf_matrix)
print("분류 보고서:")
print(report)
▶ ROC 커브 시각화
from sklearn.metrics import roc_curve
# ROC 곡선 계산
fpr, tpr, _ = roc_curve(y_test, y_pred_proba)
# 그래프 그리기
plt.figure(figsize=(6, 6))
plt.plot(fpr, tpr, color='blue', label='ROC Curve (AUC = {:.2f})'.format(auc_score))
plt.plot([0, 1], [0, 1], linestyle='--', color='gray')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend()
plt.show()
▶ 결과
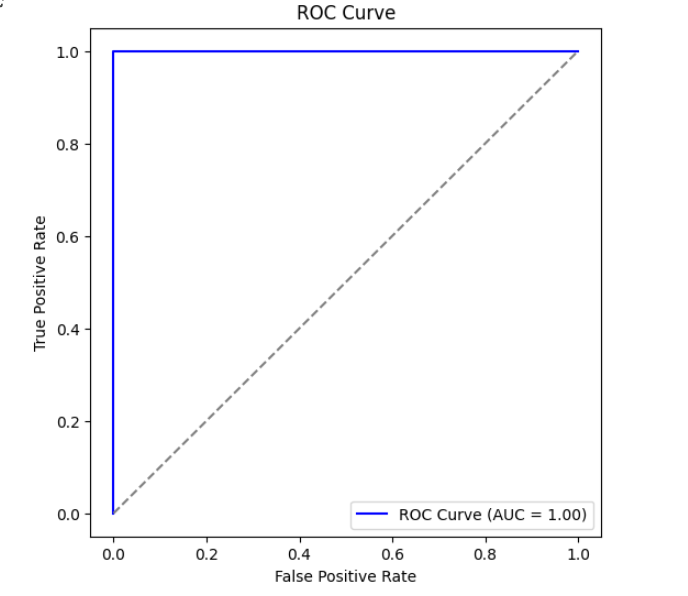
▶ 비즈니스 인사이트
- 과거 이메일 오픈 비율(past_open_rate)과 응답 시간(avg_response_time)이 중요한 요인으로 작용할 가능성이 있음
- 이메일을 많이 받은 고객이 이메일을 열 가능성이 더 낮거나, 반대로 충성 고객일 경우 열 가능성이 높을 수도 있음
- 이메일 반응 가능성이 높은 고객에게는 적극적인 마케팅을 적용하고, 반응이 낮은 고객에게는 다른 채널(SMS, 전화 등)을 고려 가능
3. 구독 기간 예측 (회귀 모델 적용)
C사는 온라인 구독 서비스를 운영하고 있으며, 신규 가입자의 초기 사용 패턴을 바탕으로 얼마나 오랫동안 구독을 유지할지를 예측하고자 한다. 이를 통해 구독 기간이 짧을 가능성이 높은 고객을 사전에 파악하여 맞춤형 혜택(할인 쿠폰, 추가 콘텐츠 제공 등)을 제공할 수 있다.
▶ 목표
- 신규 가입자의 초기 사용 데이터를 바탕으로 구독 기간(일)을 예측
- 회귀 모델(선형 회귀)을 활용하여 특정 고객이 평균적으로 몇 일 동안 구독할지를 예측
- 예측된 결과를 기반으로 고객 유지 전략을 최적화
▶ 데이터 생성
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# 가상의 신규 구독자 데이터 생성
data = {
'age': [22, 45, 25, 33, 50, 41, 29, 39, 48, 23, 31, 36, 27, 40, 53, 44, 26, 38, 51, 30],
'num_logins': [2, 15, 3, 10, 20, 12, 5, 9, 18, 4,
8, 11, 6, 13, 22, 14, 7, 10, 19, 5],
'num_watched_videos': [1, 10, 2, 7, 15, 9, 3, 6, 13, 2,
5, 8, 3, 9, 18, 11, 4, 7, 14, 4],
'avg_watch_time': [5, 40, 8, 30, 60, 35, 12, 28, 50, 6,
18, 32, 10, 33, 70, 45, 9, 29, 55, 14],
'subscription_length': [10, 45, 14, 30, 60, 50, 21, 35, 55, 12,
28, 40, 18, 42, 70, 48, 15, 37, 58, 20] # 타겟 변수
}
df = pd.DataFrame(data)
# 데이터 분할 (독립변수 X, 종속변수 y)
X = df[['age', 'num_logins', 'num_watched_videos', 'avg_watch_time']]
y = df['subscription_length']
# 훈련 데이터와 테스트 데이터로 분할 (80% 훈련, 20% 테스트)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터 정규화 (회귀 모델의 입력값을 표준화)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
▶ 선형 회귀 모델 훈련 및 평가
# 선형 회귀 모델 생성 및 학습
model = LinearRegression()
model.fit(X_train, y_train)
# 예측 수행
y_pred = model.predict(X_test)
# 성능 평가
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
# 결과 출력
print(f"MAE (평균 절대 오차): {mae:.2f}")
print(f"MSE (평균 제곱 오차): {mse:.2f}")
print(f"RMSE (제곱근 평균 제곱 오차): {rmse:.2f}")
print(f"R² (결정 계수): {r2:.2f}")
▶ 예측 결과 시각화
# 실제 값 vs 예측 값 비교 시각화
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, color='blue', alpha=0.6, label='예측 값')
plt.plot(y_test, y_test, color='red', linestyle='--', label='완벽한 예측선')
plt.xlabel("실제 구독 기간 (일)")
plt.ylabel("예측된 구독 기간 (일)")
plt.title("실제 vs 예측된 구독 기간")
plt.legend()
plt.show()
▶ 결과
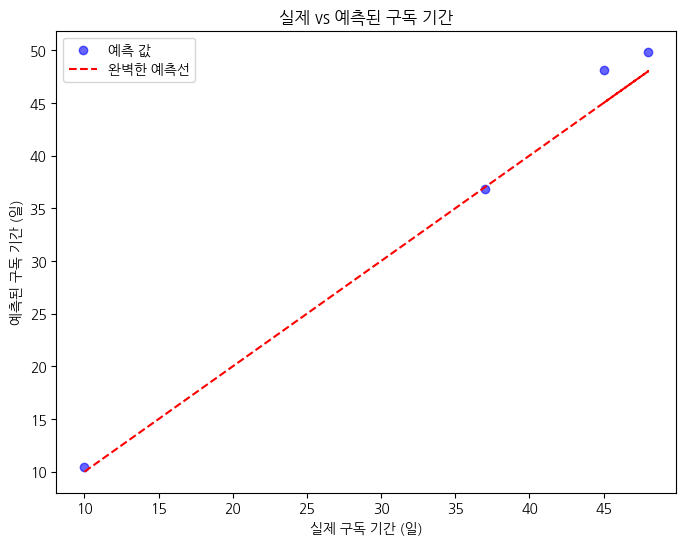
▶ 예측 예제
# 새로운 고객 데이터 예측
new_customer = np.array([[27, 8, 5, 20]]) # [나이, 로그인 수, 시청한 영상 수, 평균 시청 시간]
new_customer_scaled = scaler.transform(new_customer)
# 예측 결과 출력
predicted_subscription_length = model.predict(new_customer_scaled)
print(f"예측된 구독 기간: {predicted_subscription_length[0]:.2f} 일")
예측된 구독 기간 : 21.03일
▶ 비즈니스 인사이트
- num_logins (로그인 횟수)와 num_watched_videos (시청한 영상 수)가 많을수록 구독 기간이 길어지는 경향이 있음
- avg_watch_time (평균 시청 시간)이 길수록 구독 유지 가능성이 높음
- 예측된 결과를 활용하여 구독 기간이 짧을 가능성이 높은 고객에게 혜택을 제공하는 전략을 고려 가능
4. 고객 활동 기반 구독 플랜 추천 (다중 클래스 예측)
D사는 여러 개의 구독 플랜(베이직, 스탠다드, 프리미엄)을 제공하는 온라인 서비스 플랫폼을 운영하고 있다. 신규 가입자가 첫 7일 동안 보여주는 행동 패턴을 바탕으로, 그들이 최종적으로 어떤 구독 플랜을 선택할 가능성이 높은지 예측하고자 한다. 이를 통해, 고객 맞춤형 마케팅 전략을 수립하고 적절한 프로모션을 제공할 수 있다.
▶ 목표
- 신규 가입자의 초기 사용 데이터를 바탕으로 최종적으로 선택할 구독 플랜을 예측
- 다중 클래스 분류 모델(소프트맥스 로지스틱 회귀)을 활용하여 고객이 베이직, 스탠다드, 프리미엄 중 어떤 플랜을 선택할지 예측
- 예측된 결과를 기반으로 구독 플랜별 맞춤 마케팅 전략을 최적화
▶ 데이터 생성
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 가상의 고객 구독 플랜 데이터 생성
data = {
'age': [22, 45, 25, 33, 50, 41, 29, 39, 48, 23, 31, 36, 27, 40, 53, 44, 26, 38, 51, 30],
'num_logins': [2, 15, 3, 10, 20, 12, 5, 9, 18, 4,
8, 11, 6, 13, 22, 14, 7, 10, 19, 5],
'num_watched_videos': [1, 10, 2, 7, 15, 9, 3, 6, 13, 2,
5, 8, 3, 9, 18, 11, 4, 7, 14, 4],
'avg_watch_time': [5, 40, 8, 30, 60, 35, 12, 28, 50, 6,
18, 32, 10, 33, 70, 45, 9, 29, 55, 14],
'subscription_plan': [0, 1, 0, 1, 2, 1, 0, 1, 2, 0,
1, 1, 0, 1, 2, 1, 0, 1, 2, 0] # 다중 클래스 (0=베이직, 1=스탠다드, 2=프리미엄)
}
df = pd.DataFrame(data)
# 데이터 분할 (독립변수 X, 종속변수 y)
X = df[['age', 'num_logins', 'num_watched_videos', 'avg_watch_time']]
y = df['subscription_plan']
# 훈련 데이터와 테스트 데이터로 분할 (80% 훈련, 20% 테스트)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# 데이터 정규화 (로지스틱 회귀는 입력 스케일에 민감)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
▶ 다중 클래스 로지스틱 회귀 모델 훈련 및 평가
# 다중 클래스 로지스틱 회귀 모델 생성 (Softmax Regression)
model = LogisticRegression(multi_class='multinomial', solver='lbfgs', max_iter=200)
model.fit(X_train, y_train)
# 예측 수행
y_pred = model.predict(X_test)
# 성능 평가
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)
# 결과 출력
print(f"모델 정확도: {accuracy:.2f}")
print("혼동 행렬:")
print(conf_matrix)
print("분류 보고서:")
print(report)
▶ 시각화 혼동 행렬
import seaborn as sns
plt.figure(figsize=(6, 5))
sns.heatmap(conf_matrix, annot=True, fmt="d", cmap="Blues", xticklabels=['Basic', 'Standard', 'Premium'], yticklabels=['Basic', 'Standard', 'Premium'])
plt.xlabel("예측된 값")
plt.ylabel("실제 값")
plt.title("혼동 행렬 (Confusion Matrix)")
plt.show()▶ 결과
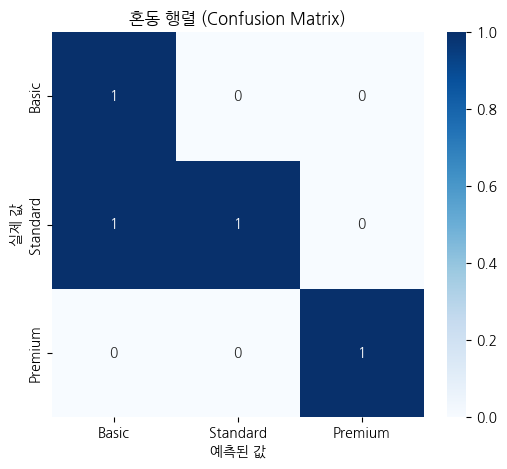
▶ 예측 예제
# 새로운 고객 데이터 예측
new_customer = np.array([[27, 8, 5, 20]]) # [나이, 로그인 수, 시청한 영상 수, 평균 시청 시간]
new_customer_scaled = scaler.transform(new_customer)
# 예측 결과 출력
predicted_plan = model.predict(new_customer_scaled)[0]
predicted_proba = model.predict_proba(new_customer_scaled)
plan_names = {0: "베이직", 1: "스탠다드", 2: "프리미엄"}
print(f"예측된 구독 플랜: {plan_names[predicted_plan]}")
print(f"각 구독 플랜 선택 확률: 베이직={predicted_proba[0][0]:.2f}, 스탠다드={predicted_proba[0][1]:.2f}, 프리미엄={predicted_proba[0][2]:.2f}")예측 결과 : 베이직
▶ 비즈니스 인사이트
- num_logins, num_watched_videos, avg_watch_time가 높을수록 상위 플랜(프리미엄) 선택 확률이 높음
- 신규 고객 중 베이직 플랜을 선택할 가능성이 높은 고객에게 스탠다드 업그레이드 혜택 제공 가능
- 스탠다드 플랜 고객 중 프리미엄 이동 가능성이 있는 고객에게 추가 혜택(추가 콘텐츠, 무료 체험 제공) 제공
5. 고객 충성도 등급 예측
E사는 고객 데이터를 활용하여 고객의 충성도를 예측하고, 이를 기반으로 맞춤형 마케팅 전략을 수립하려 한다. 고객을 다음 세 가지 충성도 등급으로 분류한다.
0 (낮음): 구매 빈도가 낮고, 재방문 가능성이 낮음
1 (중간): 일정 수준의 구매와 재방문 기록이 있음
2 (높음): 높은 구매 빈도와 충성도를 보이며, 장기 고객이 될 가능성이 큼
▶ 충성도 등급 예측 웹 서버 구축
app.py
templates/index.html


" 오늘의 회고 "
오늘은 KNN알고리즘과 SVM 의 개념을 학습하고 여러 실습을 진행한 후 마지막 두시간은 지난 시간에 배운 회귀분석 파트 실습을 했다. 코드를 작성하고 실행하고 분석하고 반복하는게 지루해 질 때 쯤 한번씩 웹 서버 연결이 껴 있는게 한숨돌리는 것 같아 좋았다. 처음 배울땐 내가 뭐하는건지도 모르고 힘들어만 했던 웹서버 인데 이제는 웹서버가 나오면 한숨 돌린다는게 신기하다.. 분석 보고서나 코드를 무한히 돌리는 것보다 어떠한 결과물이 나와서인가 더 재밌는 것 같다.
특히 오늘은 관심 분야로 가상 데이터를 생성해보고 KNN을 활용하고 또 결과물에 사진이나 링크를 다는 것도 해봐서 재밌었다 그치만 여전히 머신러닝은 어렵다..ㅜ 언제쯤 코드를 복붙하는게 아니라 직접 적을 수 있을까..ㅜㅜ
반복해서 일단 익숙해져야지..!!
오늘도 다들 고생하셨습니다 내일하루도 화이팅이에요!!